Introducing cell interactions & transformations
Introduction
PhysiCell 1.10.0 introduces a number of new features designed to simplify modeling of complex interactions and transformations. This blog post will introduce the underlying mathematics and show a complete example. We will teach this and other examples in greater depth at our upcoming Virtual PhysiCell Workshop & Hackathon (July 24-30, 2022). (Apply here!!)
Cell Interactions
In the past, it has been possible to model complex cell-cell interactions (such as those needed for microecology and immunology) by connecting basic cell functions for interaction testing and custom functions. In particular, these functions were used for the COVID19 Coalition’s open source model of SARS-CoV-2 infections and immune responses. We now build upon that work to standardize and simplify these processes, making use of the cell’s state.neighbors (a list of all cells deemed to be within mechanical interaction distance).
All the parameters for cell-cell interactions are stored in cell.phenotype.cell_interactions.
Phagocytosis
A cell can phagocytose (ingest) another cell, with rates that vary with the cell’s live/dead status or the cell type. In particular, we store:
- double dead_phagocytosis_rate : This is the rate at which a cell can phagocytose a dead cell of any type.
std::vector<double> live_phagocytosis_rates: This is a vector of phagocytosis rates for live cells of specific types. If there are n cell definitions in the simulation, then there are n rates in this vector. Please note that the index i for any cell type is its index in the list of cell definitions, not necessarily the ID of its cell definition. For safety, use one of the following to determine that index:find_cell_definition_index( int type_ID ): search for the cell definition’s index by its type ID (cell.type)find_cell_definition_index( std::string type_name ): search for the cell definition’s index by its human-readable type name (cell.type_name)
We also supply a function to help access these live phagocytosis rates.
- double& live_phagocytosis_rate( std::string type_name ) : Directly access the cell’s rate of phagocytosing the live cell type by its human-readable name. For example,
pCell->phenotype.cell_interactions.live_phagocytosis_rate( "tumor cell" ) = 0.01;
At each mechanics time step (with duration \(\Delta t\), default 0.1 minutes), each cell runs through its list of neighbors. If the neighbor is dead, its probability of phagocytosing it between \(t\) and \(t+\Delta t\) is
\[ \verb+dead_phagocytosis_rate+ \cdot \Delta t\]
If the neighbor cell is alive and its type has index j, then its probability of phagocytosing the cell between \(t\) and \(t+\Delta t\) is
\[ \verb+live_phagocytosis_rates[j]+ \cdot \Delta t\]
PhysiCell’s standardized phagocytosis model does the following:
- The phagocytosing cell will absorb the phagocytosed cell’s total solid volume into the cytoplasmic solid volume
- The phagocytosing cell will absorb the phagocytosed cell’s total fluid volume into the fluid volume
- The phagocytosing cell will absorb all of the phagocytosed cell’s internalized substrates.
- The phagocytosed cell is set to zero volume, flagged for removal, and set to not mechanically interact with remaining cells.
- The phagocytosing cell does not change its target volume. The standard volume model will gradually “digest” the absorbed volume as the cell shrinks towards its target volume.
Cell Attack
A cell can attack (cause damage to) another live cell, with rates that vary with the cell’s type. In particular, we store:
- double damage_rate : This is the rate at which a cell causes (dimensionless) damage to a target cell. The cell’s total damage is stored in cell.state.damage. The total integrated attack time is stored in
cell.state.total_attack_time. std::vector<double> attack_rates: This is a vector of attack rates for live cells of specific types. If there are n cell definitions in the simulation, then there are n rates in this vector. Please note that the index i for any cell type is its index in the list of cell definitions, not necessarily the ID of its cell definition. For safety, use one of the following to determine that index:find_cell_definition_index( int type_ID ): search for the cell definition’s index by its type ID (cell.type)find_cell_definition_index( std::string type_name ): search for the cell definition’s index by its human-readable type name (cell.type_name)
We also supply a function to help access these attack rates.
- double& attack_rate( std::string type_name ) : Directly access the cell’s rate of attacking the live cell type by its human-readable name. For example,
pCell->phenotype.cell_interactions.attack_rate( "tumor cell" ) = 0.01;
At each mechanics time step (with duration \(\Delta t\), default 0.1 minutes), each cell runs through its list of neighbors. If the neighbor cell is alive and its type has index j, then its probability of attacking the cell between \(t\) and \(t+\Delta t\) is
\[ \verb+attack_rates[j]+ \cdot \Delta t\]
To attack the cell:
- The attacking cell will increase the target cell’s damage by \( \verb+damage_rate+ \cdot \Delta t\).
- The attacking cell will increase the target cell’s total attack time by \(\Delta t\).
Note that this allows us to have variable rates of damage (e.g., some immune cells may be “worn out”), and it allows us to distinguish between damage and integrated interaction time. (For example, you may want to write a model where damage can be repaired over time.)
As of this time, PhysiCell does not have a standardized model of death in response to damage. It is up to the modeler to vary a death rate with the total attack time or integrated damage, based on their hypotheses. For example:
\[ r_\textrm{apoptosis} = r_\textrm{apoptosis,0} + \left( r_\textrm{apoptosis,max} – r_\textrm{apoptosis,0} \right) \cdot \frac{ d^h }{ d_\textrm{halfmax}^h + d^h } \]
In a phenotype function, we might write this as:
void damage_response( Cell* pCell, Phenotype& phenotype, double dt )
{ // get the base apoptosis rate from our cell definition
Cell_Definition* pCD = find_cell_definition( pCell->type_name );
double apoptosis_0 = pCD->phenotype.death.rates[0];
double apoptosis_max = 100 * apoptosis_0;
double half_max = 2.0;
double damage = pCell->state.damage;
phenotype.death.rates[0] = apoptosis_0 +
(apoptosis_max -apoptosis_0) * Hill_response_function(d,half_max,1.0);
return;
}
Cell Fusion
A cell can fuse with another live cell, with rates that vary with the cell’s type. In particular, we store:
std::vector<double> fusion_rates: This is a vector of fusion rates for live cells of specific types. If there are n cell definitions in the simulation, then there are n rates in this vector. Please note that the index i for any cell type is its index in the list of cell definitions, not necessarily the ID of its cell definition. For safety, use one of the following to determine that index:find_cell_definition_index( int type_ID ): search for the cell definition’s index by its type ID (cell.type)find_cell_definition_index( std::string type_name ): search for the cell definition’s index by its human-readable type name (cell.type_name)
We also supply a function to help access these fusion rates.
- double& fusion_rate( std::string type_name ) : Directly access the cell’s rate of fusing with the live cell type by its human-readable name. For example,
pCell->phenotype.cell_interactions.fusion_rate( "tumor cell" ) = 0.01;
At each mechanics time step (with duration \(\Delta t\), default 0.1 minutes), each cell runs through its list of neighbors. If the neighbor cell is alive and its type has index j, then its probability of fusing with the cell between \(t\) and \(t+\Delta t\) is
\[ \verb+fusion_rates[j]+ \cdot \Delta t\]
PhysiCell’s standardized fusion model does the following:
- The fusing cell will absorb the fused cell’s total cytoplasmic solid volume into the cytoplasmic solid volume
- The fusing cell will absorb the fused cell’s total nuclear volume into the nuclear solid volume
- The fusing cell will keep track of its number of nuclei in
state.number_of_nuclei. (So, if the fusing cell has 3 nuclei and the fused cell has 2 nuclei, then the new cell will have 5 nuclei.) - The fusing cell will absorb the fused cell’s total fluid volume into the fluid volume
- The fusing cell will absorb all of the fused cell’s internalized substrates.
- The fused cell is set to zero volume, flagged for removal, and set to not mechanically interact with remaining cells.
- The fused cell will be moved to the (volume weighted) center of mass of the two original cells.
- The fused cell does change its target volume to the sum of the original two cells’ target volumes. The combined cell will grow / shrink towards its new target volume.
Cell Transformations
A live cell can transform to another type (e.g., via differentiation). We store parameters for cell transformations in cell.phenotype.cell_transformations, particularly:
std::vector<double> transformation_rates: This is a vector of transformation rates from a cell’s current to type to one of the other cell types. If there are n cell definitions in the simulation, then there are n rates in this vector. Please note that the index i for any cell type is its index in the list of cell definitions, not necessarily the ID of its cell definition. For safety, use one of the following to determine that index:find_cell_definition_index( int type_ID ): search for the cell definition’s index by its type ID (cell.type)find_cell_definition_index( std::string type_name ): search for the cell definition’s index by its human-readable type name (cell.type_name)
We also supply a function to help access these transformation rates.
- double& transformation_rate( std::string type_name ) : Directly access the cell’s rate of transforming into a specific cell type by searching for its human-readable name. For example,
pCell->phenotype.cell_transformations.transformation_rate( "mutant tumor cell" ) = 0.01;
At each phenotype time step (with duration \(\Delta t\), default 6 minutes), each cell runs through the vector of transformation rates. If a (different) cell type has index j, then the cell’s probability transforming to that type between \(t\) and \(t+\Delta t\) is
\[ \verb+transformation_rates[j]+ \cdot \Delta t\]
PhysiCell uses the built-in Cell::convert_to_cell_definition( Cell_Definition& ) for the transformation.
Other New Features
This release also includes a number of handy new features:
Advanced Chemotaxis
After setting chemotaxis sensitivities in phenotype.motility and enabling the feature, cells can chemotax based on linear combinations of substrate gradients.
std::vector<double> phenotype.motility.chemotactic_sensitivitiesis a vector of chemotactic sensitivities, one for each substrate in the environment. By default, these are all zero for backwards compatibility. A positive sensitivity denotes chemotaxis up a corresponding substrate’s gradient (towards higher values), whereas a negative sensitivity gives chemotaxis against a gradient (towards lower values).- For convenience, you can access (read and write) a substrate’s chemotactic sensitivity via
phenotype.motility.chemotactic_sensitivity(name)wherenameis the human-readable name of a substrate in the simulation. - If the user sets
cell.cell_functions.update_migration_bias = advanced_chemotaxis_function, then these sensitivities are used to set the migration bias direction via: \[\vec{d}_\textrm{mot} = s_0 \nabla \rho_0 + \cdots + s_n \nabla \rho_n. \] - If the user sets
cell.cell_functions.update_migration_bias = advanced_chemotaxis_function_normalized, then these sensitivities are used to set the migration bias direction via: \[\vec{d}_\textrm{mot} = s_0 \frac{\nabla\rho_0}{|\nabla\rho_0|} + \cdots + s_n \frac{ \nabla \rho_n }{|\nabla\rho_n|}.\]
Cell Adhesion Affinities
cell.phenotype.mechanics.adhesion_affinitiesis a vector of adhesive affinities, one for each cell type in the simulation. By default, these are all one for backwards compatibility.- For convenience, you can access (read and write) a cell’s adhesive affinity for a specific cell type via
phenotype.mechanics.adhesive_affinity(name), wherenameis the human-readable name of a cell type in the simulation. - The standard mechanics function (based on potentials) uses this as follows. If cell
ihas an cell-cell adhesion strengtha_iand an adhesive affinityp_ijto cell typej, and if celljhas a cell-cell adhesion strength ofa_jand an adhesive affinityp_jito cell typei, then the strength of their adhesion is \[ \sqrt{ a_i p_{ij} \cdot a_j p_{ji} }.\] Notice that if \(a_i = a_j\) and \(p_{ij} = p_{ji}\), then this reduces to \(a_i a_{pj}\). - The standard elastic spring function (
standard_elastic_contact_function) uses this as follows. If cellihas an elastic constanta_iand an adhesive affinityp_ijto cell typej, and if celljhas an elastic constanta_jand an adhesive affinityp_jito cell typei, then the strength of their adhesion is \[ \sqrt{ a_i p_{ij} \cdot a_j p_{ji} }.\] Notice that if \(a_i = a_j\) and \(p_{ij} = p_{ji}\), then this reduces to \(a_i a_{pj}\).
Signal and Behavior Dictionaries
We will talk about this in the next blog post. See http://www.mathcancer.org/blog/introducing-cell-signal-and-behavior-dictionaries.
A brief immunology example
We will illustrate the major new functions with a simplified cancer-immune model, where tumor cells attract macrophages, which in turn attract effector T cells to damage and kill tumor cells. A mutation process will transform WT cancer cells into mutant cells that can better evade this immune response.
The problem:
We will build a simplified cancer-immune system to illustrate the new behaviors.
- WT cancer cells: Proliferate and release a signal that will stimulate an immune response. Cancer cells can transform into mutant cancer cells. Dead cells release debris. Damage increases apoptotic cell death.
- Mutant cancer cells: Proliferate but release less of the signal, as a model of immune evasion. Dead cells release debris. Damage increases apoptotic cell death.
- Macrophages: Chemotax towards the tumor signal and debris, and release a pro-inflammatory signal. They phagocytose dead cells.
- CD8+ T cells: Chemotax towards the pro-inflammatory signal and cause damage to tumor cells. As a model of immune evasion, CD8+ T cells can damage WT cancer cells faster than mutant cancer cells.
We will use the following diffusing factors:
- Tumor signal: Released by WT and mutant cells at different rates. We’ll fix a 1 min\(^{-1}\) decay rate and set the diffusion parameter to 10000 \(\mu m^2/\)min to give a 100 micron diffusion length scale.
- Pro-inflammatory signal: Released by macrophages. We’ll fix a 1 min\(^{-1}\) decay rate and set the diffusion parameter to 10000 \(\mu;m^2/\)min to give a 100 micron diffusion length scale.
- Debris: Released by dead cells. We’ll fix a 0.01 min\(^{-1}\) decay rate and choose a diffusion coefficient of 1 \(\mu;m^2/\)min for a 10 micron diffusion length scale.
In particular, we won’t worry about oxygen or resources in this model. We can use Neumann (no flux) boundary conditions.
Getting started with a template project and the graphical model builder
The PhysiCell Model Builder was developed by Randy Heiland and undergraduate researchers at Indiana University to help ease the creation of PhysiCell models, with a focus on generating correct XML configuration files that define the diffusing substrates and cell definitions. Here, we assume that you have cloned (or downloaded) the repository adjacent to your PhysiCell repository. (So that the path to PMB from PhysiCell’s root directory is ../PhysiCell-model-builder/).
Let’s start a new project (starting with the template project) from a command prompt or shell in the PhysiCell directory, and then open the model builder.
make template make python ../PhysiCell-model-builder/bin/pmb.py
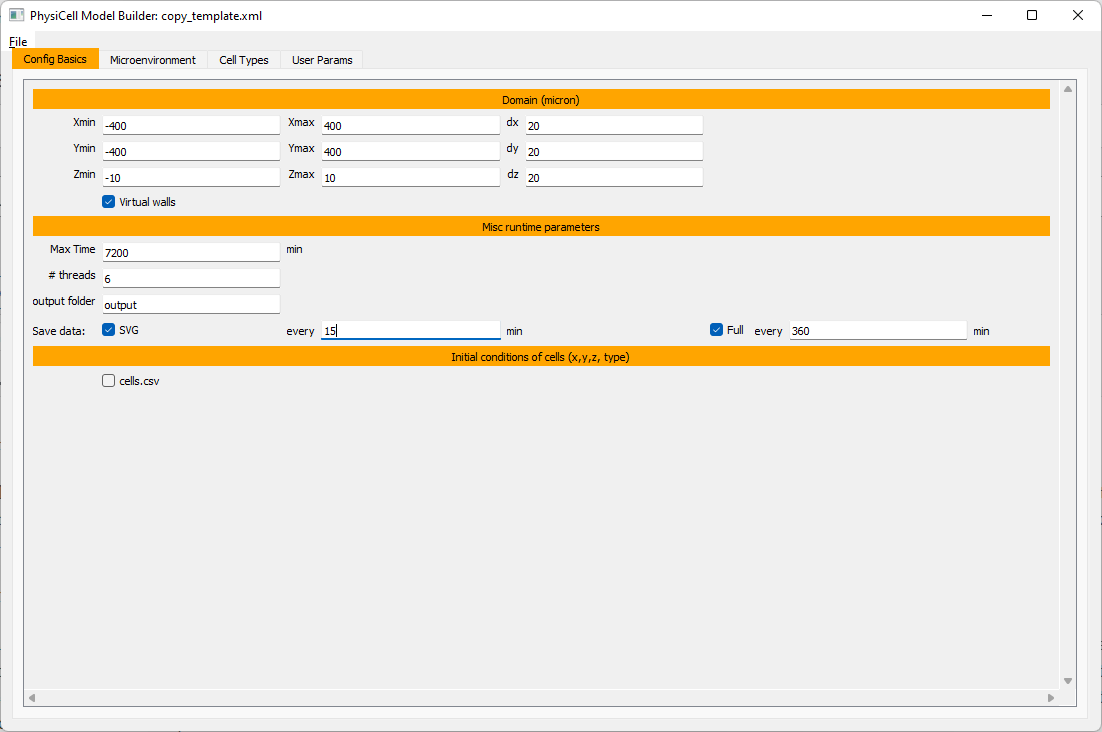
Setting up the domain
Let’s use a [-400,400] x [-400,400] 2D domain, with “virtual walls” enabled (so cells stay in the domain). We’ll run for 5760 minutes (4 days), saving SVG outputs every 15 minutes.
Setting up diffusing substrates
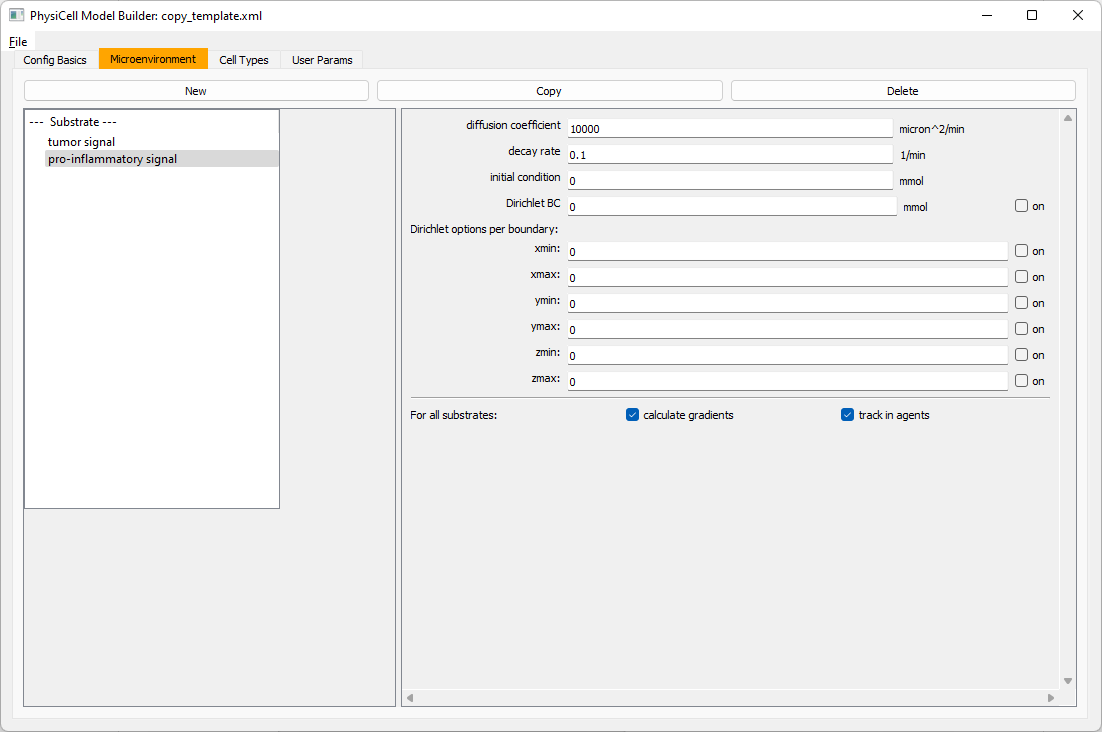
Move to the microenvironment tab. Click on substrate and rename it to tumor signal . Set the decay rate to 0.1 and diffusion parameter to 10000. Uncheck the Dirichlet condition box so that it’s a zero-flux (Neumann) boundary condition.
 Now, select
Now, select tumor signal in the lefthand column, click copy, and rename the new substrate (substrate01) to pro-inflammatory signal with the same parameters.
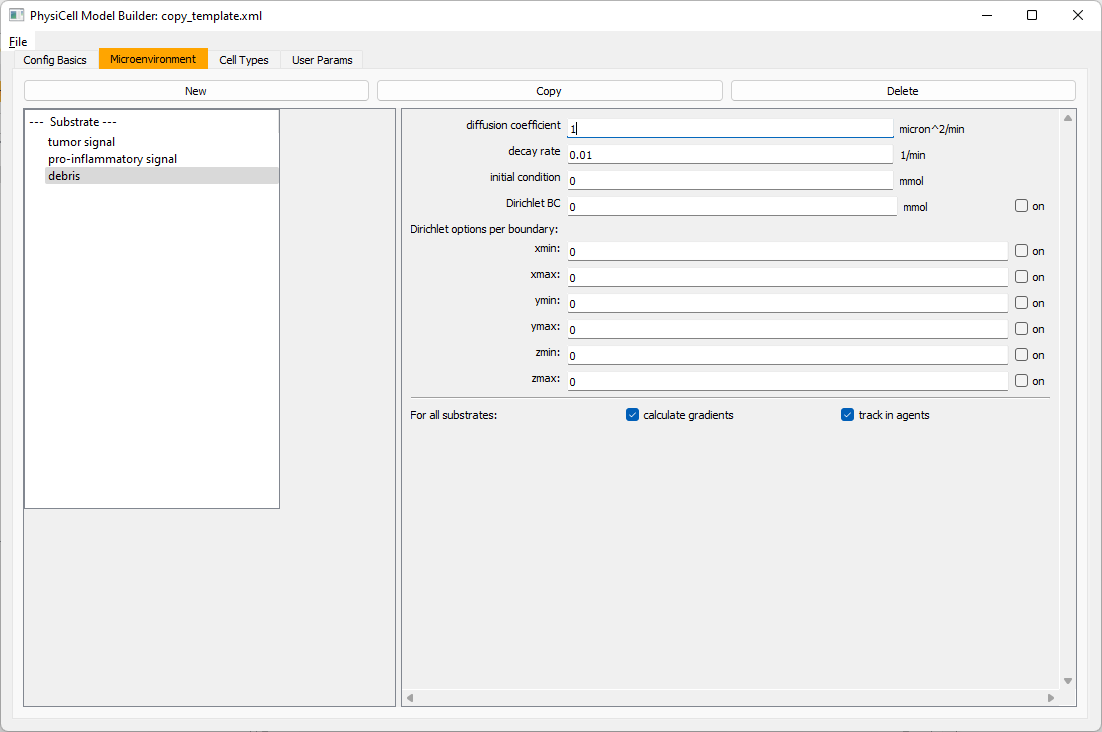
Then, copy this substrate one more time, and rename it from name debris. Set its decay rate to 0.01, and its diffusion parameter to 1.
Let’s save our work before continuing. Go to File, Save as, and save it as PhysiCell_settings.xml in your config file. (Go ahead and overwrite.)
If model builder crashes, you can reopen it, then go to File, Open, and select this file to continue editing.
Setting up the WT cancer cells
Move to the cell types tab. Click on the default cell type on the left side, and rename it to WT cancer cell. Leave most of the parameter values at their defaults. Move to the secretion sub-tab (in phenotype). From the drop-down menu, select tumor signal. Let’s set a high secretion rate of 10.
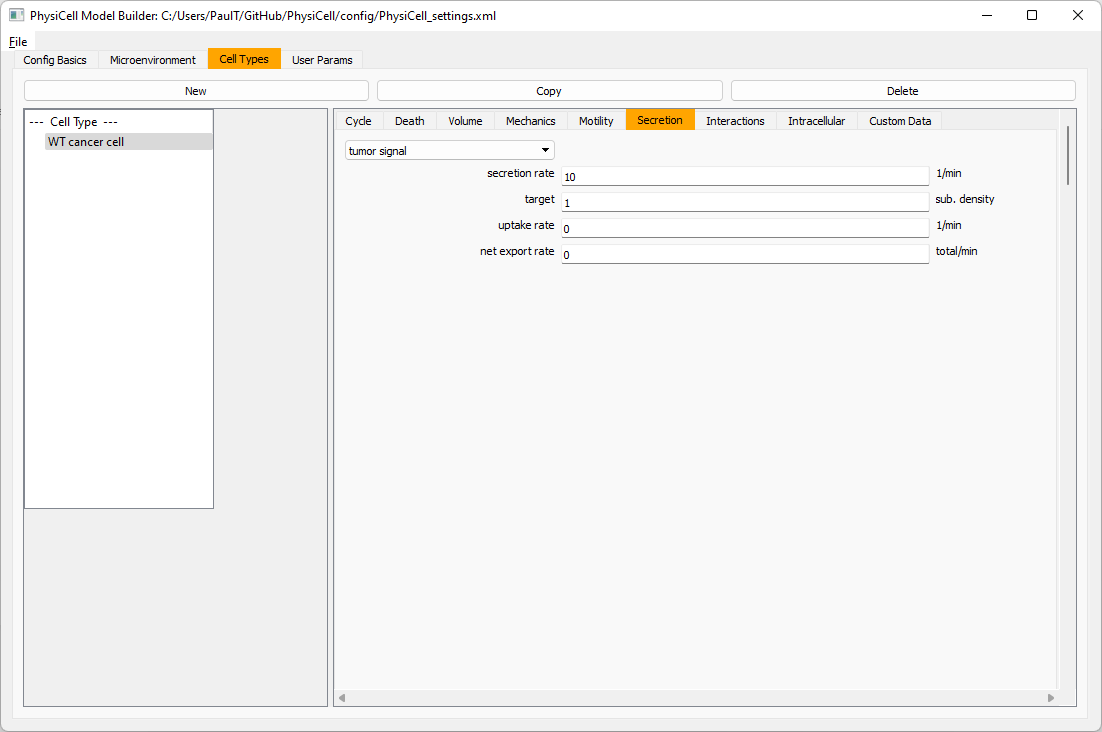
We’ll need to set WT cells as able to mutate, but before that, the model builder needs to “know” about that cell type. So, let’s move on to the next cell type for now.
Setting up mutant tumor cells
Click the WT cancer cell in the left column, and click copy. Rename this cell type (for me, it’s cell_def03) to mutant cancer cell. Click the secretion sub-tab, and set its secretion rate of tumor signal lower to 0.1.
Set the WT mutation rate
Now that both cell types are in the simulation, we can set up mutation. Let’s suppose the mean time to a mutation is 10000 minutes, or a rate of 0.0001 min\(^{-1}\).
Click the WT cancer cell in the left column to select it. Go to the interactions tab. Go down to transformation rate, and choose mutant cancer cell from the drop-down menu. Set its rate to 0.0001.

Create macrophages
Now click on the WT cancer cell type in the left column, and click copy to create a new cell type. Click on the new type (for me cell_def04) and rename it to macrophage.
Click on cycle and change to a live cells and change from a duration representation to a transition rate representation. Keep its cycling rate at 0.
Go to death and change from duration to transition rate for both apoptosis and necrosis, and keep the death rates at 0.0
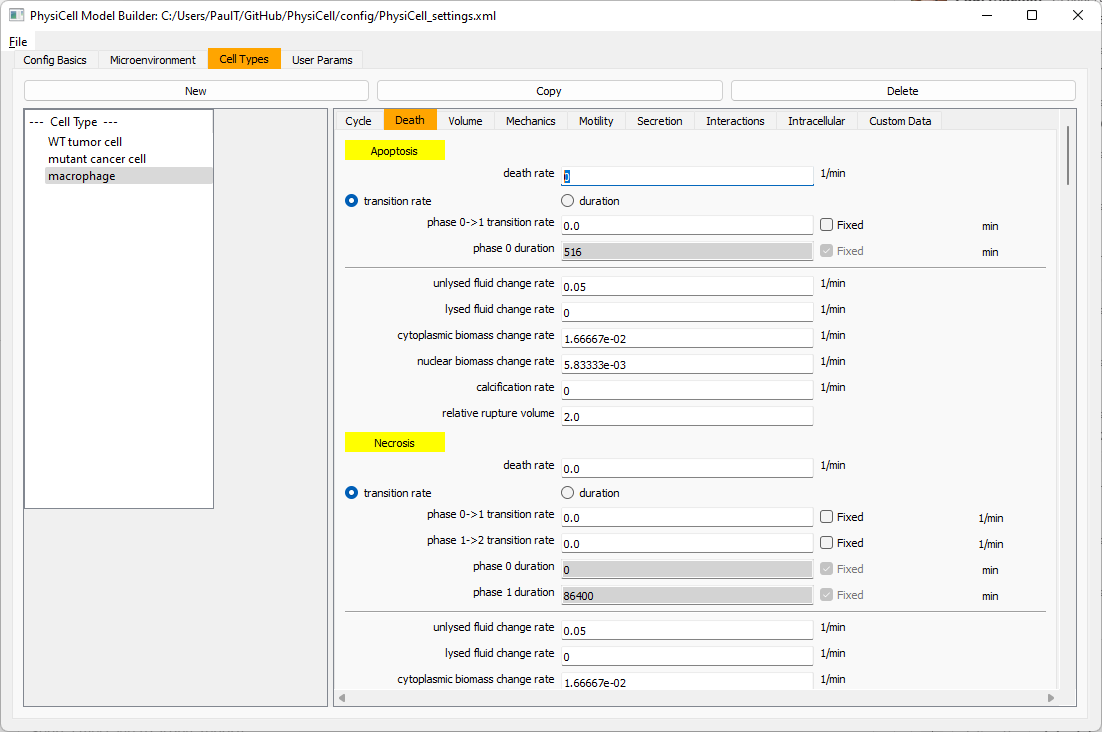
Now, go to the motility tab. Set the speed to 1 \(\mu m/\)min, persistence time to 5 min, and migration bias to 0.5. Be sure to enable motility. Then, enable advanced motility. Choose tumor signal from the drop-down and set its sensitivity to 1.0. Then choose debris from the drop-down and set its sensitivity to 0.1
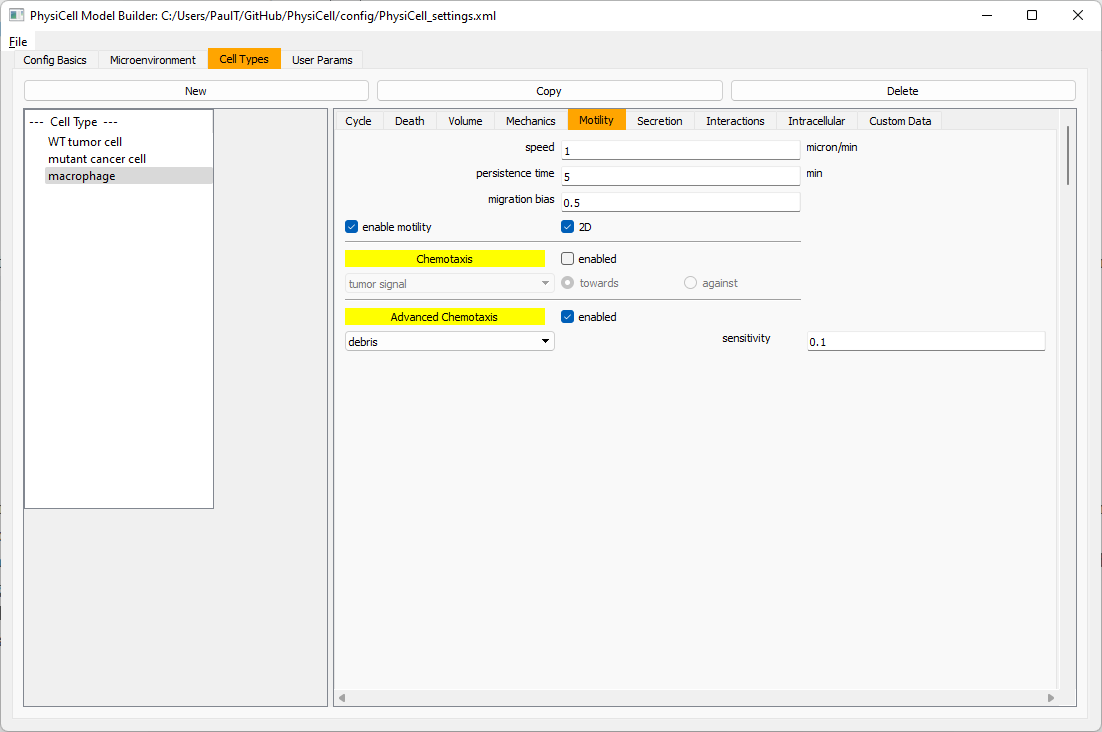
Now, let’s make sure it secretes pro-inflammatory signal. Go to the secretion tab. Choose tumor signal from the drop-down, and make sure its secretion rate is 0. Then choose pro-inflammatory signal from the drop-down, set its secretion rate to 100, and its target value to 1.

Lastly, let’s set macrophages up to phagocytose dead cells. Go to the interactions tab. Set the dead phagocytosis rate to 0.05 (so that the mean contact time to wait to eat a dead cell is 1/0.05 = 20 minutes). This would be a good time to save your work.
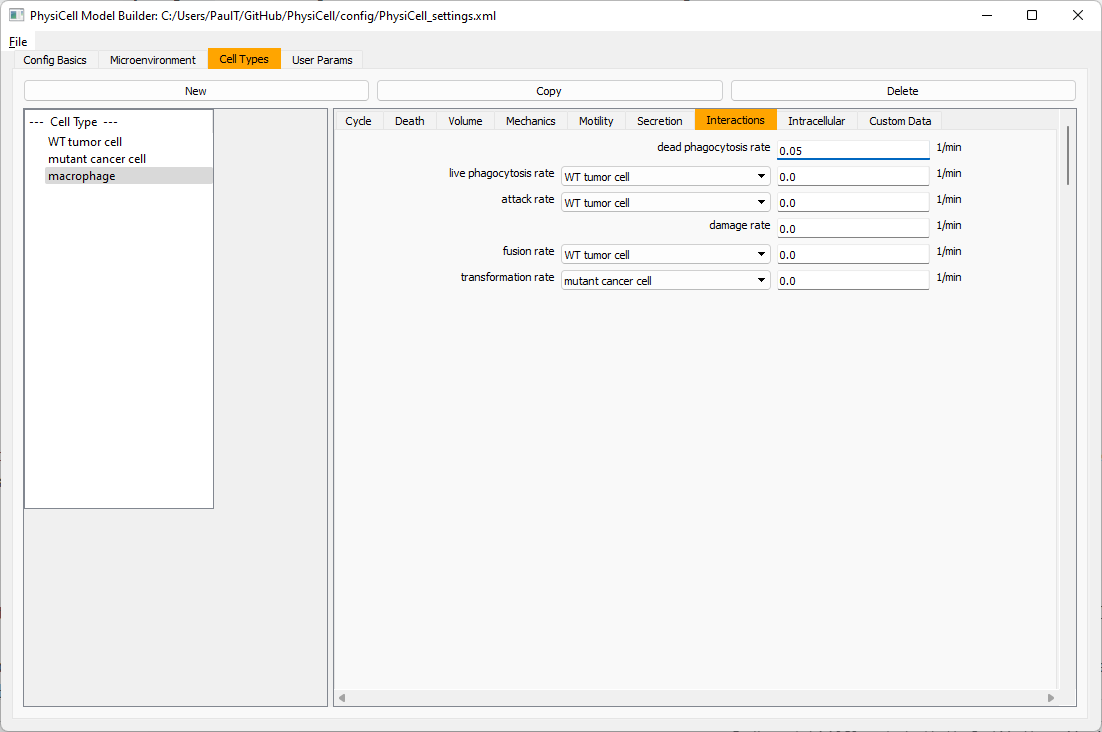
Macrophages probably shouldn’t be adhesive. So go to the mechanics sub-tab, and set the cell-cell adhesion strength to 0.0.
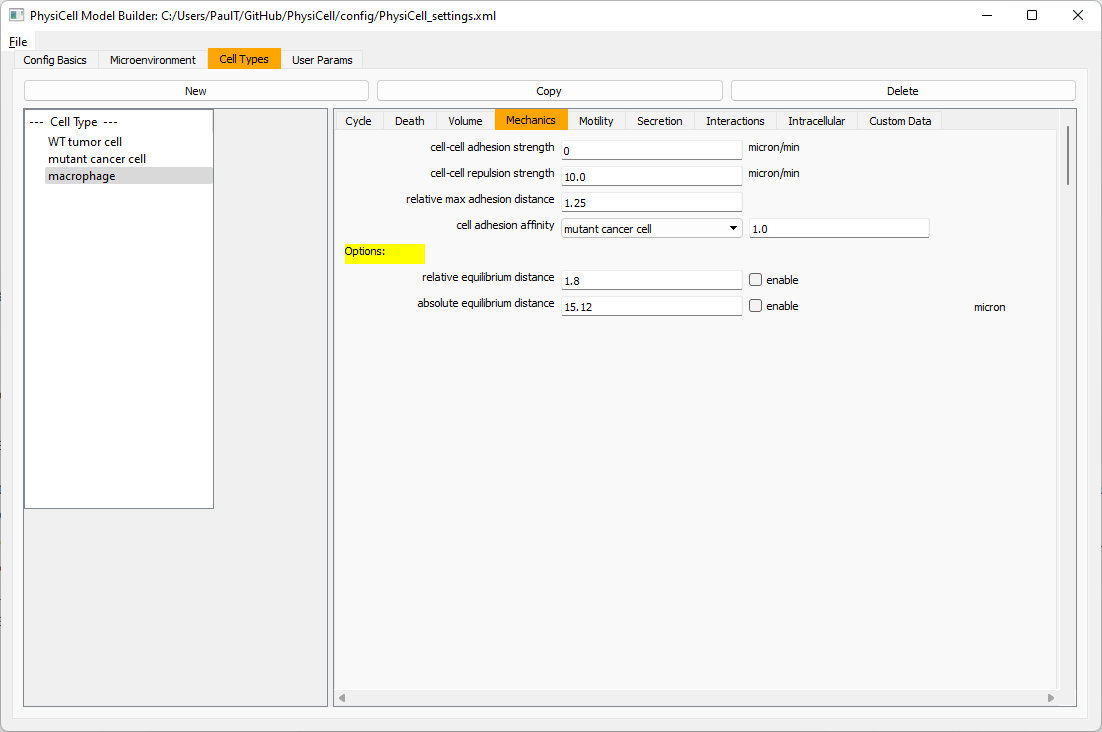
Create CD8+ T cells
Select macrophage on the left column, and choose copy. Rename the new cell type to CD8+ T cell. Go to the secretion sub-tab and make sure to set the secretion rate of pro-inflammatory signal to 0.0.
Now, let’s use simpler chemotaxis for these towards pro-inflammatory signal. Go to the motility tab. Uncheck advanced chemotaxis and check chemotaxis. Choose pro-inflammatory signal from the drop-down, with the towards option.
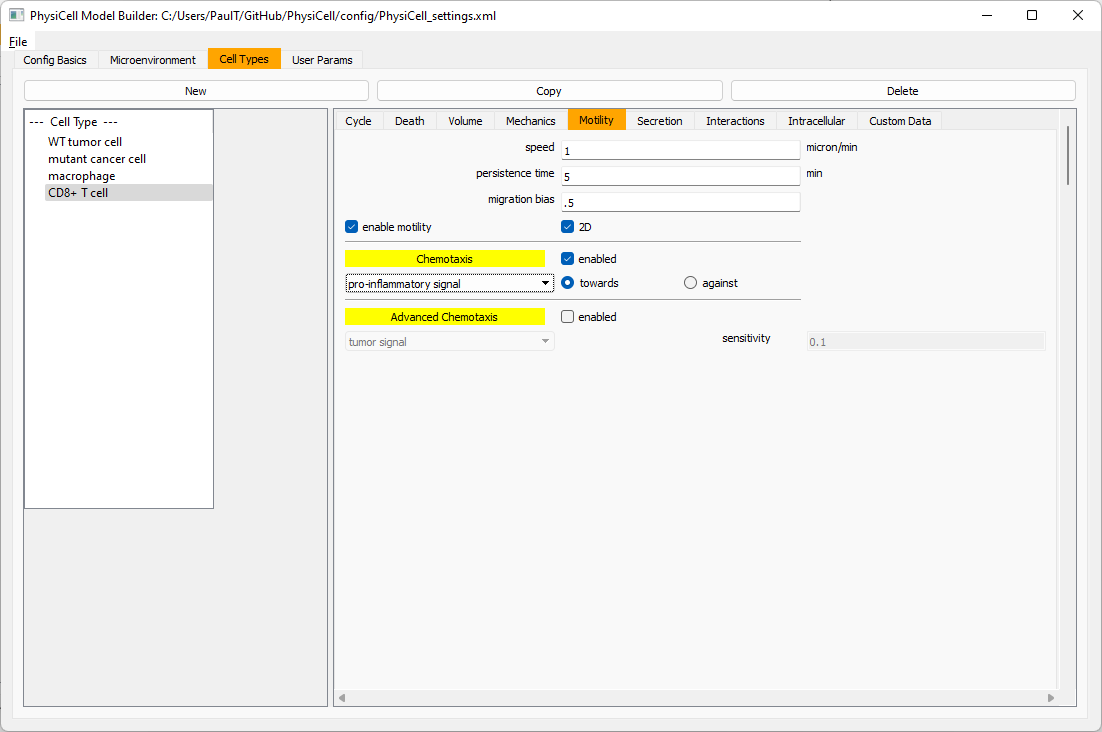
Lastly, let’s set these cells to attack WT and tumor cells. Go to the interactions tab. Set the dead phagocytosis rate to 0.
Now, let’s work on attack. Set the damage rate to 1.0. Near attack rate, choose WT tumor cell from the drop-down, and set its attack rate to 10 (so it attacks during any 0.1 minute interval). Then choose mutant tumor cell from the drop-down, and set its attack rate to 1 (as a model of immune evasion, where they are less likely to attack a non-WT tumor cell).

Set the initial cell conditions
Go to the user params tab. On number of cells, choose 50. It will randomly place 50 of each cell type at the start of the simulation.
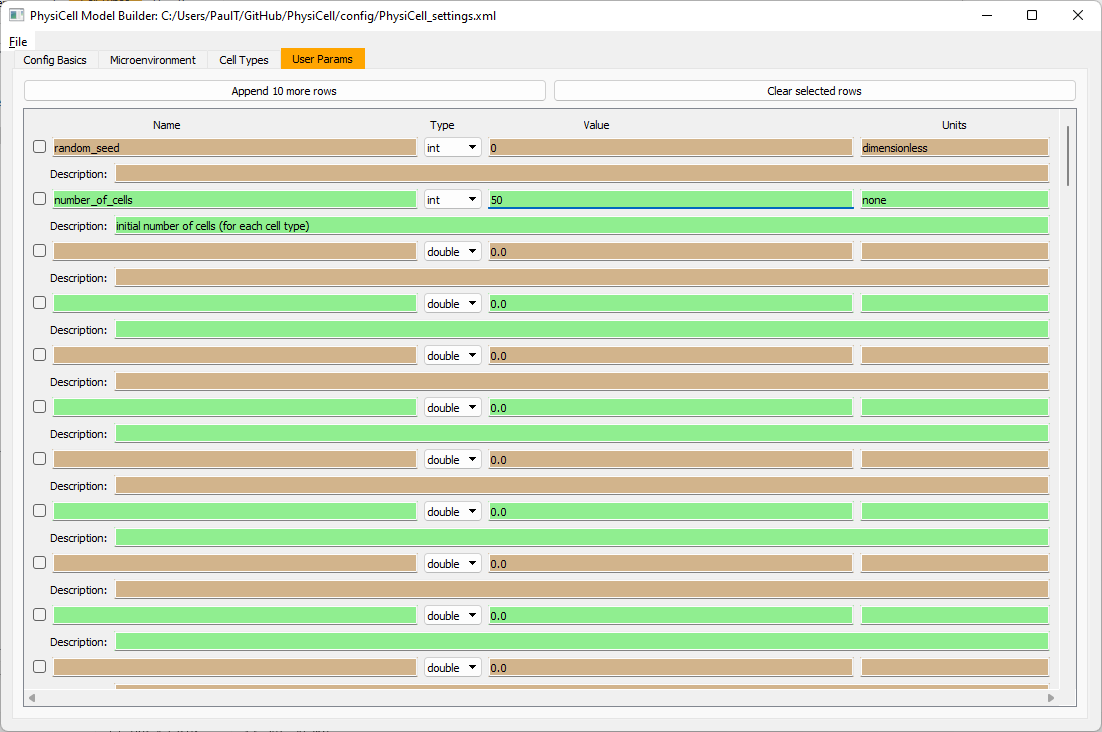
That’s all! Go to File and save (or save as), and overwrite config/PhysiCell_settings.xml. Then close the model builder.
Testing the model
Go into the PhysiCell directory. Since you already compiled, just run your model (which will use PhysiCell_settings.xml that you just saved to the config directory). For Linux or MacOS (or similar Unix-like systems):
./project
Windows users would type project without the ./ at the front.
Take a look at your SVG outputs in the output directory. You might consider making an animated gif (make gif) or a movie:
make jpeg && make movie
Here’s what we have.
 |
Promising! But we still need to write a little C++ so that damage kills tumor cells, and so that dead tumor cells release debris. (And we could stand to “anchor” tumor cells to ECM so they don’t get pushed around by the immune cells, but that’s a post for another day!)
Customizing the WT and mutant tumor cells with phenotype functions
First, open custom.h in the custom_modules directory, and declare a function for tumor phenotype:
void tumor_phenotype_function( Cell* pCell, Phenotype& phenotype, double dt );
Now, let’s open custom.cpp to write this function at the bottom. Here’s what we’ll do:
- If dead, set rate of debris release to 1.0 and return.
- Otherwise, we’ll set damage-based apoptosis.
- Get the base apoptosis rate
- Get the current damage
- Use a Hill response function with a half-max of 36, max apoptosis rate of 0.05 min\(^{-1}\), and a hill power of 2.0
Here’s the code:
void tumor_phenotype_function( Cell* pCell, Phenotype& phenotype, double dt )
{
// find my cell definition
static Cell_Definition* pCD = find_cell_definition( pCell->type_name );
// find the index of debris in the environment
static int nDebris = microenvironment.find_density_index( "debris" );
static int nTS = microenvironment.find_density_index( "tumor signal" );
// if dead: release debris. stop releasing tumor signal
if( phenotype.death.dead == true )
{
phenotype.secretion.secretion_rates[nDebris] = 1;
phenotype.secretion.saturation_densities[nDebris] = 1;
phenotype.secretion.secretion_rates[nTS] = 0;
// last time I'll execute this function (special optional trick)
pCell->functions.update_phenotype = NULL;
return;
}
// damage increases death
// find death model
static int nApoptosis =
phenotype.death.find_death_model_index( PhysiCell_constants::apoptosis_death_model );
double signal = pCell->state.damage; // current damage
double base_val = pCD->phenotype.death.rates[nApoptosis]; // base death rate (from cell def)
double max_val = 0.05; // max death rate (at large damage)
static double damage_halfmax = 36.0;
double hill_power = 2.0;
// evaluate Hill response function
double hill = Hill_response_function( signal , damage_halfmax , hill_power );
// set "dose-dependent" death rate
phenotype.death.rates[nApoptosis] = base_val + (max_val-base_val)*hill;
return;
}
Now, we need to make sure we apply these functions to tumor cell. Go to `create_cell_types` and look just before we display the cell definitions. We need to:
- Search for the WT tumor cell definition
- Set the update_phenotype function for that type to the tumor_phenotype_function we just wrote
- Repeat for the mutant tumor cell type.
Here’s the code:
...
/*
Put any modifications to individual cell definitions here.
This is a good place to set custom functions.
*/
cell_defaults.functions.update_phenotype = phenotype_function;
cell_defaults.functions.custom_cell_rule = custom_function;
cell_defaults.functions.contact_function = contact_function;
Cell_Definition* pCD = find_cell_definition( "WT cancer cell");
pCD->functions.update_phenotype = tumor_phenotype_function;
pCD = find_cell_definition( "mutant cancer cell");
pCD->functions.update_phenotype = tumor_phenotype_function;
/*
This builds the map of cell definitions and summarizes the setup.
*/
display_cell_definitions( std::cout );
return;
}
That’s it! Let’s recompile and run!
make && ./project
And here’s the final movie.
|
Much better! Now the
Coming up next!
We will use the signal and behavior dictionaries to help us easily write C++ functions to modulate the tumor and immune cell behaviors.
Once ready, this will be posted at http://www.mathcancer.org/blog/introducing-cell-signal-and-behavior-dictionaries/.
PhysiCell Tools : python-loader
The newest tool for PhysiCell provides an easy way to load your PhysiCell output data into python for analysis. This builds upon previous work on loading data into MATLAB. A post on that tool can be found at:
http://www.mathcancer.org/blog/working-with-physicell-snapshots-in-matlab/.
PhysiCell stores output data as a MultiCell Digital Snapshot (MultiCellDS) that consists of several files for each time step and is probably stored in your ./output directory. pyMCDS is a python object that is initialized with the .xml file
What you’ll need
- python-loader, available on GitHub at
- Python 3.x, recommended distribution available at
- A number of Python packages, included in anaconda or available through pip
- NumPy
- pandas
- scipy
- Some PhysiCell data, probably in your ./output directory
Anatomy of a MultiCell Digital Snapshot
Each time PhysiCell’s internal time tracker passes a time step where data is to be saved, it generates a number of files of various types. Each of these files will have a number at the end that indicates where it belongs in the sequence of outputs. All of the files from the first round of output will end in 00000000.* and the second round will be 00000001.* and so on. Let’s say we’re interested in a set of output from partway through the run, the 88th set of output files. The files we care about most from this set consists of:
- output00000087.xml: This file is the main organizer of the data. It contains an overview of the data stored in the MultiCellDS as well as some actual data including:
- Metadata about the time and runtime for the current time step
- Coordinates for the computational domain
- Parameters for diffusing substrates in the microenvironment
- Column labels for the cell data
- File names for the files that contain microenvironment and cell data at this time step
- output00000087_microenvironment0.mat: This is a MATLAB matrix file that contains all of the data about the microenvironment at this time step
- output00000087_cells_physicell.mat: This is a MATLAB matrix file that contains all of the tracked information about the individual cells in the model. It tells us things like the cells’ position, volume, secretion, cell cycle status, and user-defined cell parameters.
Setup
Using pyMCDS
From the appropriate file in your PhysiCell directory, wherever pyMCDS.py lives, you can use the data loader in your own scripts or in an interactive session. To start you have to import the pyMCDS class
from pyMCDS import pyMCDS
Loading the data
Data is loaded into python from the MultiCellDS by initializing the pyMCDS object. The initialization function for pyMCDS takes one required and one optional argument.
__init__(xml_file, [output_path = '.'])
'''
xml_file : string
String containing the name of the output xml file
output_path :
String containing the path (relative or absolute) to the directory
where PhysiCell output files are stored
'''
We are interested in reading output00000087.xml that lives in ~/path/to/PhysiCell/output (don’t worry Windows paths work too). We would initialize our pyMCDS object using those names and the actual data would be stored in a member dictionary called data.
mcds = pyMCDS('output00000087.xml', '~/path/to/PhysiCell/output')
# Now our data lives in:
mcds.data
We’ve tried to keep everything organized inside of this dictionary but let’s take a look at what we actually have in here. Of course in real output, there will probably not be a chemical named my_chemical, this is simply there to illustrate how multiple chemicals are handled.

The data member dictionary is a dictionary of dictionaries whose child dictionaries can be accessed through normal python dictionary syntax.
mcds.data['metadata'] mcds.data['continuum_variables']['my_chemical']
Each of these subdictionaries contains data, we will take a look at exactly what that data is and how it can be accessed in the following sections.
Metadata
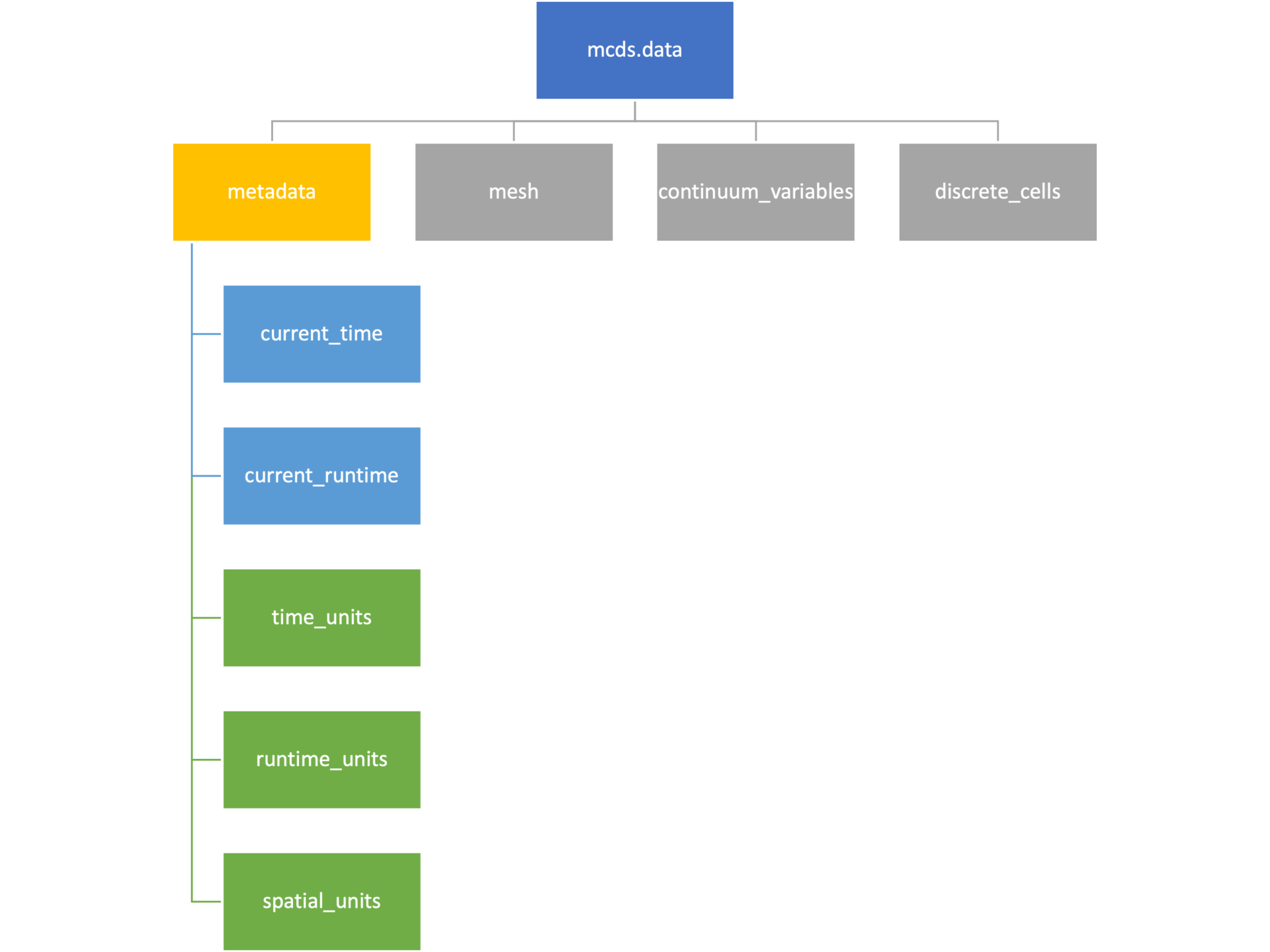
The metadata dictionary contains information about the time of the simulation as well as units for both times and space. Here and in later sections blue boxes indicate scalars and green boxes indicate strings. We can access each of these things using normal dictionary syntax. We’ve also got access to a helper function get_time() for the common operation of retrieving the simulation time.
>>> mcds.data['metadata']['time_units'] 'min' >>> mcds.get_time() 5220.0
Mesh
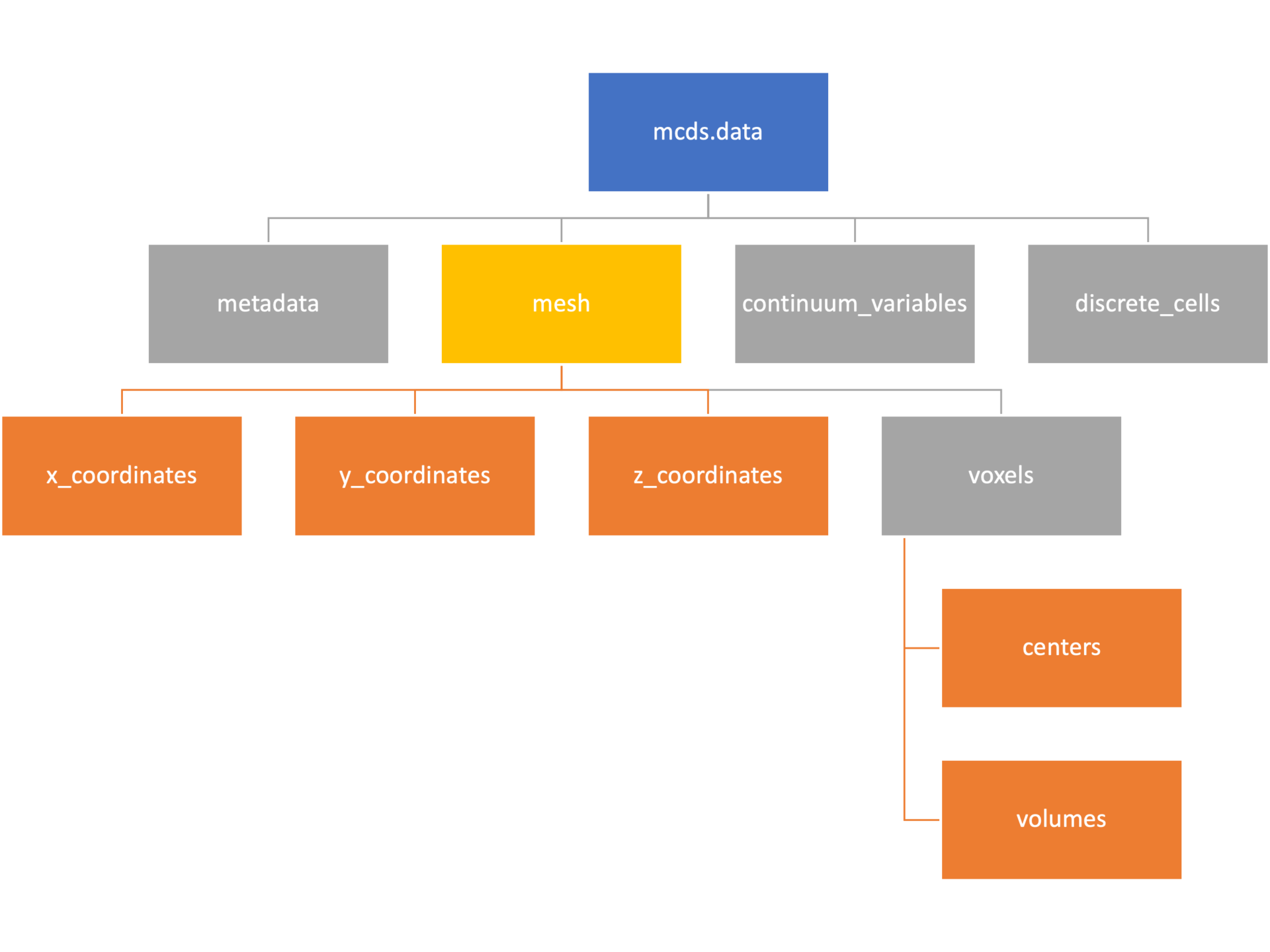
The mesh dictionary has a lot more going on than the metadata dictionary. It contains three numpy arrays, indicated by orange boxes, as well as another dictionary. The three arrays contain \(x\), \(y\) and \(z\) coordinates for the centers of the voxels that constiture the computational domain in a meshgrid format. This means that each of those arrays is tensors of rank three. Together they identify the coordinates of each possible point in the space.
In contrast, the arrays in the voxel dictionary are stored linearly. If we know that we care about voxel number 42, we want to use the stuff in the voxels dictionary. If we want to make a contour plot, we want to use the x_coordinates, y_coordinates, and z_coordinates arrays.
# We can extract one of the meshgrid arrays as a numpy array
>>> y_coords = mcds.data['mesh']['y_coordinates']
>>> y_coords.shape
(75, 75, 75)
>>> y_coords[0, 0, :4]
array([-740., -740., -740., -740.])
# We can also extract the array of voxel centers
>>> centers = mcds.data['mesh']['voxels']['centers']
>>> centers.shape
(3, 421875)
>>> centers[:, :4]
array([[-740., -720., -700., -680.],
[-740., -740., -740., -740.],
[-740., -740., -740., -740.]])
# We have a handy function to quickly extract the components of the full meshgrid
>>> xx, yy, zz = mcds.get_mesh()
>>> yy.shape
(75, 75, 75)
>>> yy[0, 0, :4]
array([-740., -740., -740., -740.])
# We can also use this to return the meshgrid describing an x, y plane
>>> xx, yy = mcds.get_2D_mesh()
>>> yy.shape
(75, 75)
Continuum variables
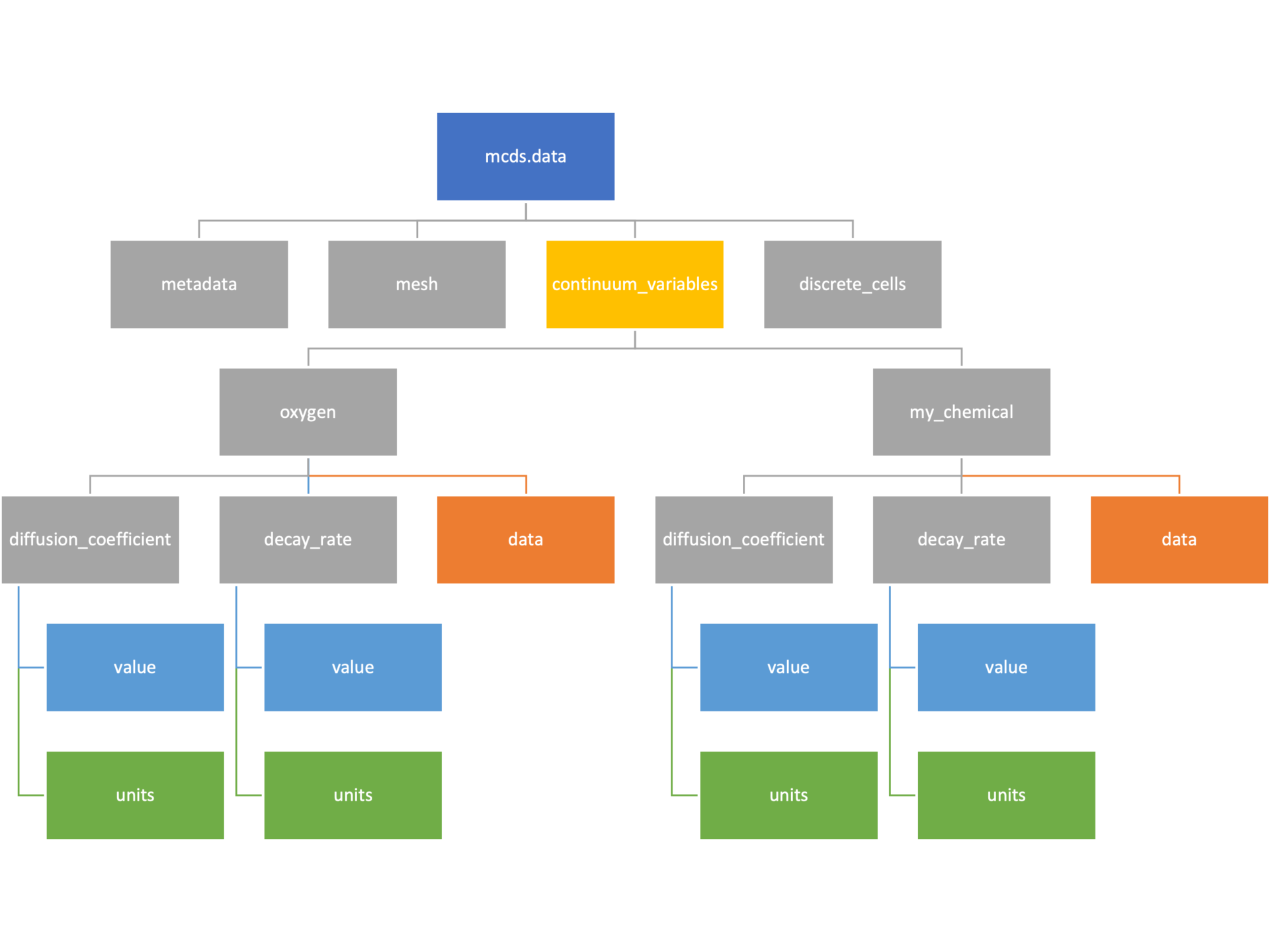
The continuum_variables dictionary is the most complicated of the four. It contains subdictionaries that we access using the names of each of the chemicals in the microenvironment. In our toy example above, these are oxygen and my_chemical. If our model tracked diffusing oxygen, VEGF, and glucose, then the continuum_variables dictionary would contain a subdirectory for each of them.
For a particular chemical species in the microenvironment we have two more dictionaries called decay_rate and diffusion_coefficient, and a numpy array called data. The diffusion and decay dictionaries each complete the value stored as a scalar and the unit stored as a string. The numpy array contains the concentrations of the chemical in each voxel at this time and is the same shape as the meshgrids of the computational domain stored in the .data[‘mesh’] arrays.
# we need to know the names of the substrates to work with
# this data. We have a function to help us find them.
>>> mcds.get_substrate_names()
['oxygen', 'my_chemical']
# The diffusable chemical dictionaries are messy
# if we need to do a lot with them it might be easier
# to put them into their own instance
>>> oxy_dict = mcds.data['continuum_variables']['oxygen']
>>> oxy_dict['decay_rate']
{'value': 0.1, 'units': '1/min'}
# What we care about most is probably the numpy
# array of concentrations
>>> oxy_conc = oxy_dict['data']
>>> oxy_conc.shape
(75, 75, 75)
# Alternatively, we can get the same array with a function
>>> oxy_conc2 = mcds.get_concentrations('oxygen')
>>> oxy_conc2.shape
(75, 75, 75)
# We can also get the concentrations on a plane using the
# same function and supplying a z value to "slice through"
# note that right now the z_value must be an exact match
# for a plane of voxel centers, in the future we may add
# interpolation.
>>> oxy_plane = mcds.get_concentrations('oxygen', z_value=100.0)
>>> oxy_plane.shape
(75, 75)
# we can also find the concentration in a single voxel using the
# position of a point within that voxel. This will give us an
# array of all concentrations at that point.
>>> mcds.get_concentrations_at(x=0., y=550., z=0.)
array([17.94514446, 0.99113448])
Discrete Cells
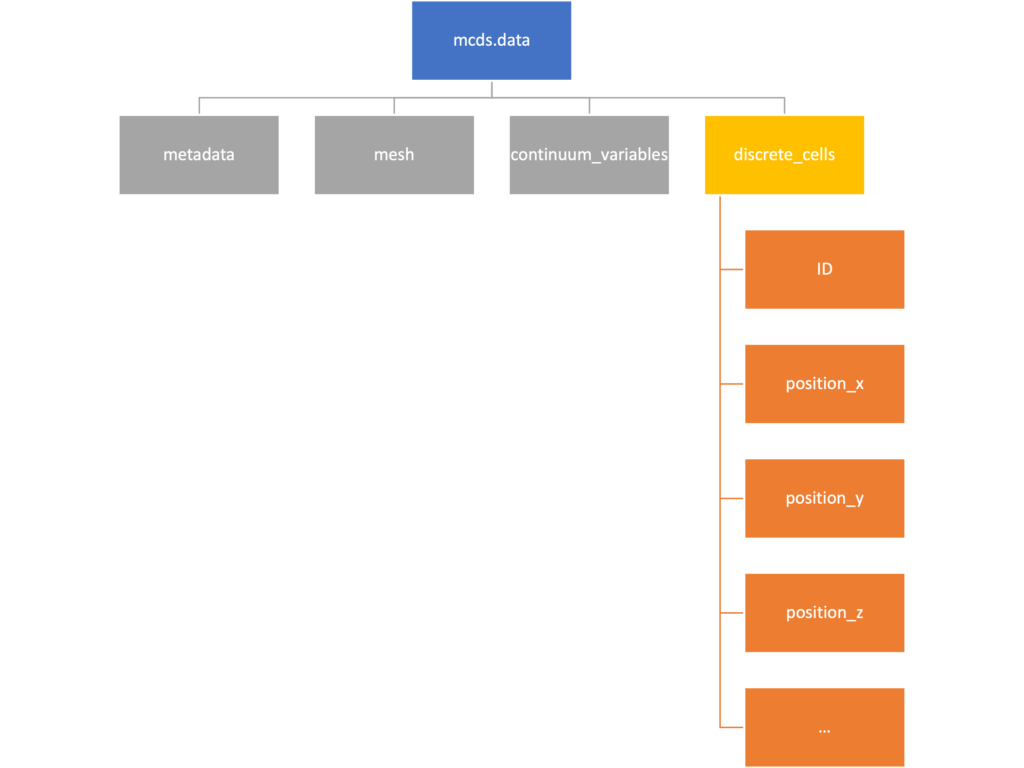
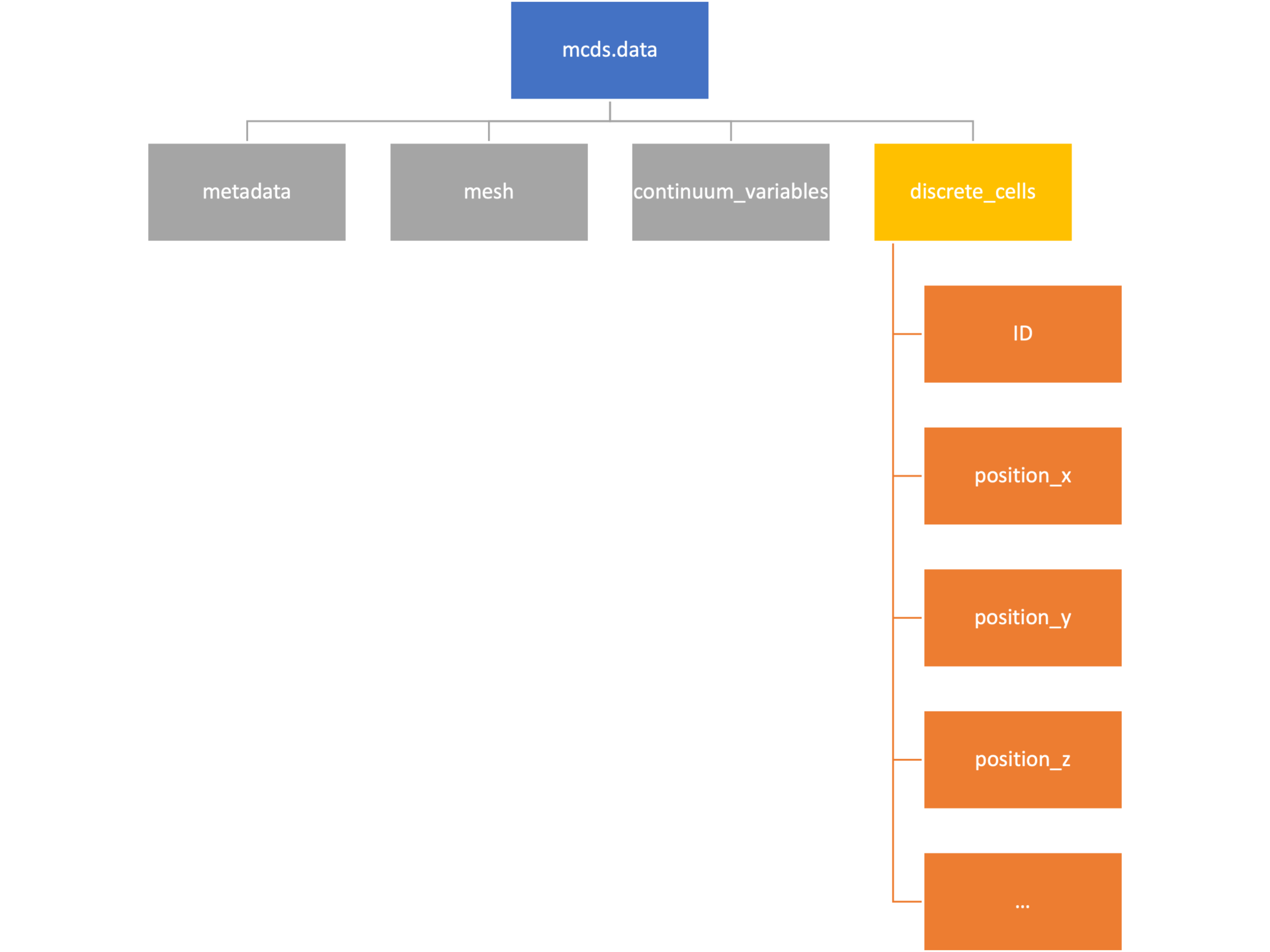
The discrete cells dictionary is relatively straightforward. It contains a number of numpy arrays that contain information regarding individual cells. These are all 1-dimensional arrays and each corresponds to one of the variables specified in the output*.xml file. With the default settings, these are:
- ID: unique integer that will identify the cell throughout its lifetime in the simulation
- position(_x, _y, _z): floating point positions for the cell in \(x\), \(y\), and \(z\) directions
- total_volume: total volume of the cell
- cell_type: integer label for the cell as used in PhysiCell
- cycle_model: integer label for the cell cycle model as used in PhysiCell
- current_phase: integer specification for which phase of the cycle model the cell is currently in
- elapsed_time_in_phase: time that cell has been in current phase of cell cycle model
- nuclear_volume: volume of cell nucleus
- cytoplasmic_volume: volume of cell cytoplasm
- fluid_fraction: proportion of the volume due to fliud
- calcified_fraction: proportion of volume consisting of calcified material
- orientation(_x, _y, _z): direction in which cell is pointing
- polarity:
- migration_speed: current speed of cell
- motility_vector(_x, _y, _z): current direction of movement of cell
- migration_bias: coefficient for stochastic movement (higher is “more deterministic”)
- motility_bias_direction(_x, _y, _z): direction of movement bias
- persistence_time: time in-between direction changes for cell
- motility_reserved:
# Extracting single variables is just like before
>>> cell_ids = mcds.data['discrete_cells']['ID']
>>> cell_ids.shape
(18595,)
>>> cell_ids[:4]
array([0., 1., 2., 3.])
# If we're clever we can extract 2D arrays
>>> cell_vec = np.zeros((cell_ids.shape[0], 3))
>>> vec_list = ['position_x', 'position_y', 'position_z']
>>> for i, lab in enumerate(vec_list):
... cell_vec[:, i] = mcds.data['discrete_cells'][lab]
...
array([[ -69.72657128, -39.02046405, -233.63178904],
[ -69.84507464, -22.71693265, -233.59277388],
[ -69.84891462, -6.04070516, -233.61816711],
[ -69.845265 , 10.80035554, -233.61667313]])
# We can get the list of all of the variables stored in this dictionary
>>> mcds.get_cell_variables()
['ID',
'position_x',
'position_y',
'position_z',
'total_volume',
'cell_type',
'cycle_model',
'current_phase',
'elapsed_time_in_phase',
'nuclear_volume',
'cytoplasmic_volume',
'fluid_fraction',
'calcified_fraction',
'orientation_x',
'orientation_y',
'orientation_z',
'polarity',
'migration_speed',
'motility_vector_x',
'motility_vector_y',
'motility_vector_z',
'migration_bias',
'motility_bias_direction_x',
'motility_bias_direction_y',
'motility_bias_direction_z',
'persistence_time',
'motility_reserved',
'oncoprotein',
'elastic_coefficient',
'kill_rate',
'attachment_lifetime',
'attachment_rate']
# We can also get all of the cell data as a pandas DataFrame
>>> cell_df = mcds.get_cell_df()
>>> cell_df.head()
ID position_x position_y position_z total_volume cell_type cycle_model ...
0.0 - 69.726571 - 39.020464 - 233.631789 2494.0 0.0 5.0 ...
1.0 - 69.845075 - 22.716933 - 233.592774 2494.0 0.0 5.0 ...
2.0 - 69.848915 - 6.040705 - 233.618167 2494.0 0.0 5.0 ...
3.0 - 69.845265 10.800356 - 233.616673 2494.0 0.0 5.0 ...
4.0 - 69.828161 27.324530 - 233.631579 2494.0 0.0 5.0 ...
# if we want to we can also get just the subset of cells that
# are in a specific voxel
>>> vox_df = mcds.get_cell_df_at(x=0.0, y=550.0, z=0.0)
>>> vox_df.iloc[:, :5]
ID position_x position_y position_z total_volume
26718 228761.0 6.623617 536.709341 -1.282934 2454.814507
52736 270274.0 -7.990034 538.184921 9.648955 1523.386488
Examples
These examples will not be made using our toy dataset described above but will instead be made using a single timepoint dataset that can be found at:
Substrate contour plot
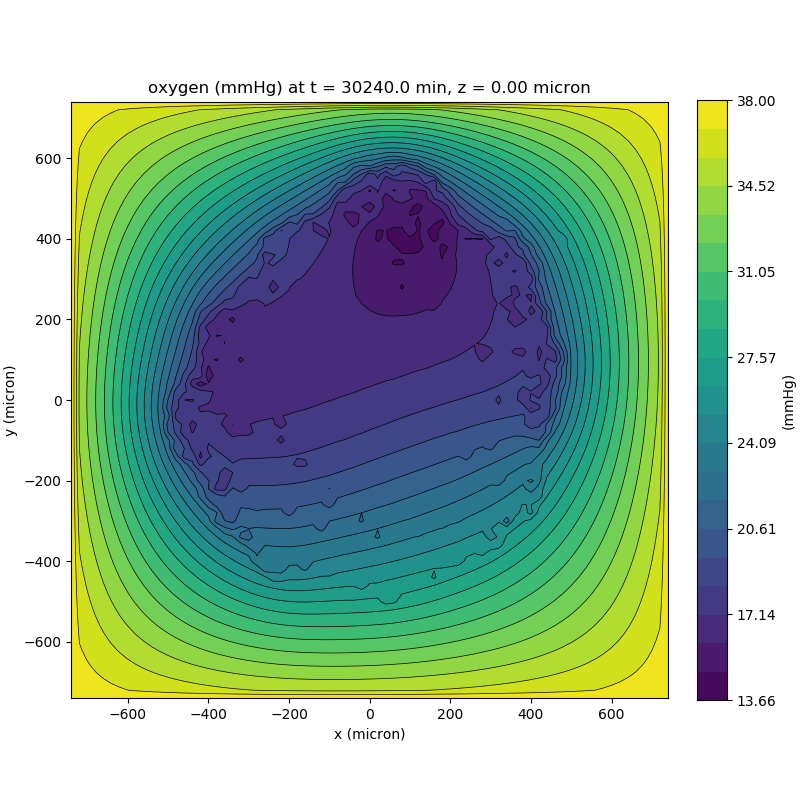
One of the big advantages of working with PhysiCell data in python is that we have access to its plotting tools. For the sake of example let’s plot the partial pressure of oxygen throughout the computational domain along the \(z = 0\) plane. Once we’ve loaded our data by initializing a pyMCDS object, we can work entirely within python to produce the plot.
from pyMCDS import pyMCDS
import numpy as np
import matplotlib.pyplot as plt
# load data
mcds = pyMCDS('output00003696.xml', '../output')
# Set our z plane and get our substrate values along it
z_val = 0.00
plane_oxy = mcds.get_concentrations('oxygen', z_slice=z_val)
# Get the 2D mesh for contour plotting
xx, yy = mcds.get_mesh()
# We want to be able to control the number of contour levels so we
# need to do a little set up
num_levels = 21
min_conc = plane_oxy.min()
max_conc = plane_oxy.max()
my_levels = np.linspace(min_conc, max_conc, num_levels)
# set up the figure area and add data layers
fig, ax = plt.subplot()
cs = ax.contourf(xx, yy, plane_oxy, levels=my_levels)
ax.contour(xx, yy, plane_oxy, color='black', levels = my_levels,
linewidths=0.5)
# Now we need to add our color bar
cbar1 = fig.colorbar(cs, shrink=0.75)
cbar1.set_label('mmHg')
# Let's put the time in to make these look nice
ax.set_aspect('equal')
ax.set_xlabel('x (micron)')
ax.set_ylabel('y (micron)')
ax.set_title('oxygen (mmHg) at t = {:.1f} {:s}, z = {:.2f} {:s}'.format(
mcds.get_time(),
mcds.data['metadata']['time_units'],
z_val,
mcds.data['metadata']['spatial_units'])
plt.show()
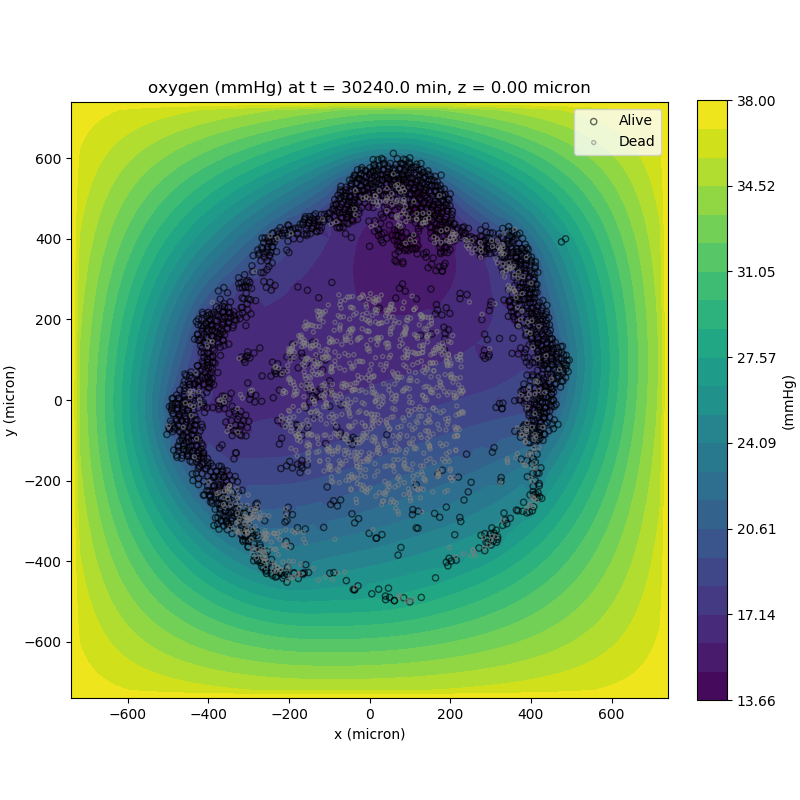
Adding a cells layer
We can also use pandas to do fairly complex selections of cells to add to our plots. Below we use pandas and the previous plot to add a cells layer.
from pyMCDS import pyMCDS
import numpy as np
import matplotlib.pyplot as plt
# load data
mcds = pyMCDS('output00003696.xml', '../output')
# Set our z plane and get our substrate values along it
z_val = 0.00
plane_oxy = mcds.get_concentrations('oxygen', z_slice=z_val)
# Get the 2D mesh for contour plotting
xx, yy = mcds.get_mesh()
# We want to be able to control the number of contour levels so we
# need to do a little set up
num_levels = 21
min_conc = plane_oxy.min()
max_conc = plane_oxy.max()
my_levels = np.linspace(min_conc, max_conc, num_levels)
# get our cells data and figure out which cells are in the plane
cell_df = mcds.get_cell_df()
ds = mcds.get_mesh_spacing()
inside_plane = (cell_df['position_z'] < z_val + ds) \ & (cell_df['position_z'] > z_val - ds)
plane_cells = cell_df[inside_plane]
# We're going to plot two types of cells and we want it to look nice
colors = ['black', 'grey']
sizes = [20, 8]
labels = ['Alive', 'Dead']
# set up the figure area and add microenvironment layer
fig, ax = plt.subplot()
cs = ax.contourf(xx, yy, plane_oxy, levels=my_levels)
# get our cells of interest
# alive_cells = plane_cells[plane_cells['cycle_model'] < 6]
# dead_cells = plane_cells[plane_cells['cycle_model'] > 6]
# -- for newer versions of PhysiCell
alive_cells = plane_cells[plane_cells['cycle_model'] < 100]
dead_cells = plane_cells[plane_cells['cycle_model'] >= 100]
# plot the cell layer
for i, plot_cells in enumerate((alive_cells, dead_cells)):
ax.scatter(plot_cells['position_x'].values,
plot_cells['position_y'].values,
facecolor='none',
edgecolors=colors[i],
alpha=0.6,
s=sizes[i],
label=labels[i])
# Now we need to add our color bar
cbar1 = fig.colorbar(cs, shrink=0.75)
cbar1.set_label('mmHg')
# Let's put the time in to make these look nice
ax.set_aspect('equal')
ax.set_xlabel('x (micron)')
ax.set_ylabel('y (micron)')
ax.set_title('oxygen (mmHg) at t = {:.1f} {:s}, z = {:.2f} {:s}'.format(
mcds.get_time(),
mcds.data['metadata']['time_units'],
z_val,
mcds.data['metadata']['spatial_units'])
ax.legend(loc='upper right')
plt.show()
Future Direction
The first extension of this project will be timeseries functionality. This will provide similar data loading functionality but for a time series of MultiCell Digital Snapshots instead of simply one point in time.
PhysiCell Tools : PhysiCell-povwriter
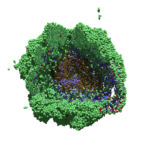
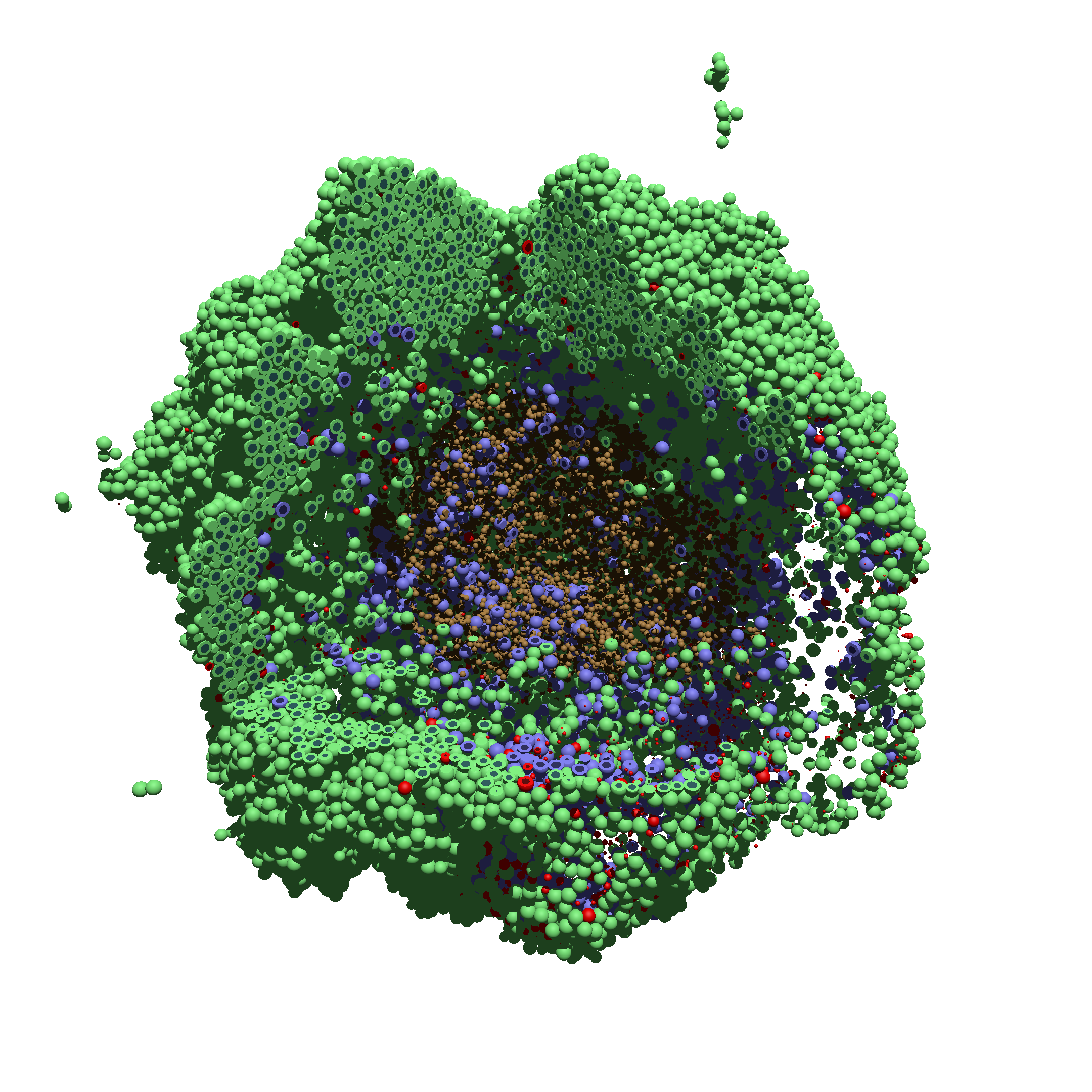
As PhysiCell matures, we are starting to turn our attention to better training materials and an ecosystem of open source PhysiCell tools. PhysiCell-povwriter is is designed to help transform your 3-D simulation results into 3-D visualizations like this one:
PhysiCell-povwriter transforms simulation snapshots into 3-D scenes that can be rendered into still images using POV-ray: an open source software package that uses raytracing to mimic the path of light from a source of illumination to a single viewpoint (a camera or an eye). The result is a beautifully rendered scene (at any resolution you choose) with very nice shading and lighting.
If you repeat this on many simulation snapshots, you can create an animation of your work.
What you’ll need
This workflow is entirely based on open source software:
- 3-D simulation data (likely stored in ./output from your project)
- PhysiCell-povwriter, available on GitHub at
- POV-ray, available at
- ImageMagick (optional, for image file conversions)
- mencoder (optional, for making compressed movies)
Setup
Building PhysiCell-povwriter
After you clone PhysiCell-povwriter or download its source from a release, you’ll need to compile it. In the project’s root directory, compile the project by:
make
(If you need to set up a C++ PhysiCell development environment, click here for OSX or here for Windows.)
Next, copy povwriter (povwriter.exe in Windows) to either the root directory of your PhysiCell project, or somewhere in your path. Copy ./config/povwriter-settings.xml to the ./config directory of your PhysiCell project.
Editing resolutions in POV-ray
PhysiCell-povwriter is intended for creating “square” images, but POV-ray does not have any pre-created square rendering resolutions out-of-the-box. However, this is straightforward to fix.
- Open POV-Ray
- Go to the “tools” menu and select “edit resolution INI file”
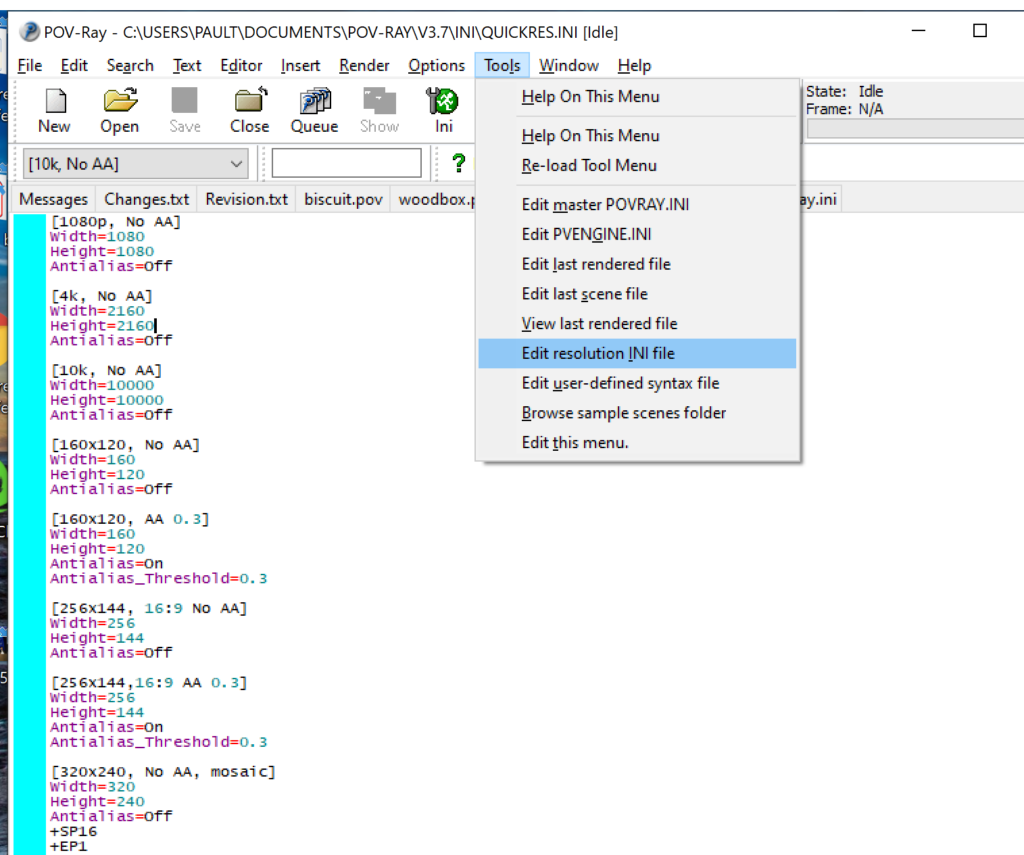
- At the top of the INI file (which opens for editing in POV-ray), make a new profile:
[1080x1080, AA] Width=480 Height=480 Antialias=On
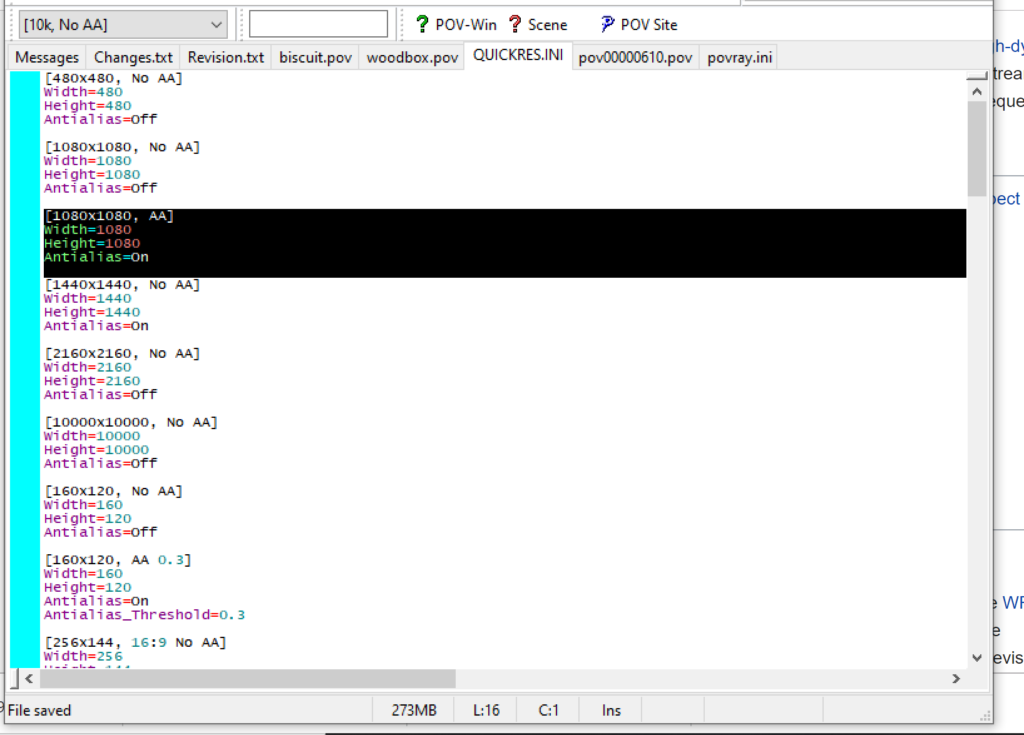
- Make similar profiles (with unique names) to suit your preferences. I suggest one at 480×480 (as a fast preview), another at 2160×2160, and another at 5000×5000 (because they will be absurdly high resolution). For example:
[2160x2160 no AA] Width=2160 Height=2160 Antialias=Off
You can optionally make more profiles with antialiasing on (which provides some smoothing for areas of high detail), but you’re probably better off just rendering without antialiasing at higher resolutions and the scaling the image down as needed. Also, rendering without antialiasing will be faster.
- Once done making profiles, save and exit POV-Ray.
- The next time you open POV-Ray, your new resolution profiles will be available in the lefthand dropdown box.

Configuring PhysiCell-povwriter
Once you have copied povwriter-settings.xml to your project’s config file, open it in a text editor. Below, we’ll show the different settings.
Camera settings
<camera> <distance_from_origin units="micron">1500</distance_from_origin> <xy_angle>3.92699081699</xy_angle> <!-- 5*pi/4 --> <yz_angle>1.0471975512</yz_angle> <!-- pi/3 --> </camera>
For simplicity, PhysiCell-POVray (currently) always aims the camera towards the origin (0,0,0), with “up” towards the positive z-axis. distance_from_origin sets how far the camera is placed from the origin. xy_angle sets the angle \(\theta\) from the positive x-axis in the xy-plane. yz_angle sets the angle \(\phi\) from the positive z-axis in the yz-plane. Both angles are in radians.
Options
<options> <use_standard_colors>true</use_standard_colors> <nuclear_offset units="micron">0.1</nuclear_offset> <cell_bound units="micron">750</cell_bound> <threads>8</threads> </options>
use_standard_colors (if set to true) uses a built-in “paint-by-numbers” color scheme, where each cell type (identified with an integer) gets XML-defined colors for live, apoptotic, and dead cells. More on this below. If use_standard_colors is set to false, then PhysiCell-povwriter uses the my_pigment_and_finish_function in ./custom_modules/povwriter.cpp to color cells.
The nuclear_offset is a small additional height given to nuclei when cropping to avoid visual artifacts when rendering (which can cause some “tearing” or “bleeding” between the rendered nucleus and cytoplasm). cell_bound is used for leaving some cells out of bound: any cell with |x|, |y|, or |z| exceeding cell_bound will not be rendered. threads is used for parallelizing on multicore processors; note that it only speeds up povwriter if you are converting multiple PhysiCell outputs to povray files.
Save
<save> <!-- done --> <folder>output</folder> <!-- use . for root --> <filebase>output</filebase> <time_index>3696</time_index> </save>
Use folder to tell PhysiCell-povwriter where the data files are stored. Use filebase to tell how the outputs are named. Typically, they have the form output########_cells_physicell.mat; in this case, the filebase is output. Lastly, use time_index to set the output number. For example if your file is output00000182_cells_physicell.mat, then filebase = output and time_index = 182.
Below, we’ll see how to specify ranges of indices at the command line, which would supersede the time_index given here in the XML.
Clipping planes
PhysiCell-povwriter uses clipping planes to help create cutaway views of the simulations. By default, 3 clipping planes are used to cut out an octant of the viewing area.
Recall that a plane can be defined by its normal vector n and a point p on the plane. With these, the plane can be defined as all points x satisfying
\[ \left( \vec{x} -\vec{p} \right) \cdot \vec{n} = 0 \]
These are then written out as a plane equation
\[ a x + by + cz + d = 0, \]
where
\[ (a,b,c) = \vec{n} \hspace{.5in} \textrm{ and } \hspace{0.5in} d = \: – \vec{n} \cdot \vec{p}. \]
As of Version 1.0.0, we are having some difficulties with clipping planes that do not pass through the origin (0,0,0), for which \( d = 0 \).
In the config file, these planes are written as \( (a,b,c,d) \):
<clipping_planes> <!-- done --> <clipping_plane>0,-1,0,0</clipping_plane> <clipping_plane>-1,0,0,0</clipping_plane> <clipping_plane>0,0,1,0</clipping_plane> </clipping_planes>
Note that cells “behind” the plane (where \( ( \vec{x} – \vec{p} ) \cdot \vec{n} \le 0 \)) are rendered, and cells in “front” of the plane (where \( (\vec{x}-\vec{p}) \cdot \vec{n} > 0 \)) are not rendered. Cells that intersect the plane are partially rendered (using constructive geometry via union and intersection commands in POV-ray).
Cell color definitions
Within <cell_color_definitions>, you’ll find multiple <cell_colors> blocks, each of which defines the live, dead, and necrotic colors for a specific cell type (with the type ID indicated in the attribute). These colors are only applied if use_standard_colors is set to true in options. See above.
The live colors are given as two rgb (red,green,blue) colors for the cytoplasm and nucleus of live cells. Each element of this triple can range from 0 to 1, and not from 0 to 255 as in many raw image formats. Next, finish specifies ambient (how much highly-scattered background ambient light illuminates the cell), diffuse (how well light rays can illuminate the surface), and specular (how much of a shiny reflective splotch the cell gets).
See the POV-ray documentation for for information on the finish.
This is repeated to give the apoptotic and necrotic colors for the cell type.
<cell_colors type="0"> <live> <cytoplasm>.25,1,.25</cytoplasm> <!-- red,green,blue --> <nuclear>0.03,0.125</nuclear> <finish>0.05,1,0.1</finish> <!-- ambient,diffuse,specular --> </live> <apoptotic> <cytoplasm>1,0,0</cytoplasm> <!-- red,green,blue --> <nuclear>0.125,0,0</nuclear> <finish>0.05,1,0.1</finish> <!-- ambient,diffuse,specular --> </apoptotic> <necrotic> <cytoplasm>1,0.5412,0.1490</cytoplasm> <!-- red,green,blue --> <nuclear>0.125,0.06765,0.018625</nuclear> <finish>0.01,0.5,0.1</finish> <!-- ambient,diffuse,specular --> </necrotic> </cell_colors>
Use multiple cell_colors blocks (each with type corresponding to the integer cell type) to define the colors of multiple cell types.
Using PhysiCell-povwriter
Use by the XML configuration file alone
The simplest syntax:
physicell$ ./povwriter
(Windows users: povwriter or povwriter.exe) will process ./config/povwriter-settings.xml and convert the single indicated PhysiCell snapshot to a .pov file.
If you run POV-writer with the default configuration file in the povwriter structure (with the supplied sample data), it will render time index 3696 from the immunotherapy example in our 2018 PhysiCell Method Paper:
physicell$ ./povwriter povwriter version 1.0.0 ================================================================================ Copyright (c) Paul Macklin 2019, on behalf of the PhysiCell project OSI License: BSD-3-Clause (see LICENSE.txt) Usage: ================================================================================ povwriter : run povwriter with config file ./config/settings.xml povwriter FILENAME.xml : run povwriter with config file FILENAME.xml povwriter x:y:z : run povwriter on data in FOLDER with indices from x to y in incremenets of z Example: ./povwriter 0:2:10 processes files: ./FOLDER/FILEBASE00000000_physicell_cells.mat ./FOLDER/FILEBASE00000002_physicell_cells.mat ... ./FOLDER/FILEBASE00000010_physicell_cells.mat (See the config file to set FOLDER and FILEBASE) povwriter x1,...,xn : run povwriter on data in FOLDER with indices x1,...,xn Example: ./povwriter 1,3,17 processes files: ./FOLDER/FILEBASE00000001_physicell_cells.mat ./FOLDER/FILEBASE00000003_physicell_cells.mat ./FOLDER/FILEBASE00000017_physicell_cells.mat (Note that there are no spaces.) (See the config file to set FOLDER and FILEBASE) Code updates at https://github.com/PhysiCell-Tools/PhysiCell-povwriter Tutorial & documentation at http://MathCancer.org/blog/povwriter ================================================================================ Using config file ./config/povwriter-settings.xml ... Using standard coloring function ... Found 3 clipping planes ... Found 2 cell color definitions ... Processing file ./output/output00003696_cells_physicell.mat... Matrix size: 32 x 66978 Creating file pov00003696.pov for output ... Writing 66978 cells ... done! Done processing all 1 files!
The result is a single POV-ray file (pov00003696.pov) in the root directory.
Now, open that file in POV-ray (double-click the file if you are in Windows), choose one of your resolutions in your lefthand dropdown (I’ll choose 2160×2160 no antialiasing), and click the green “run” button.
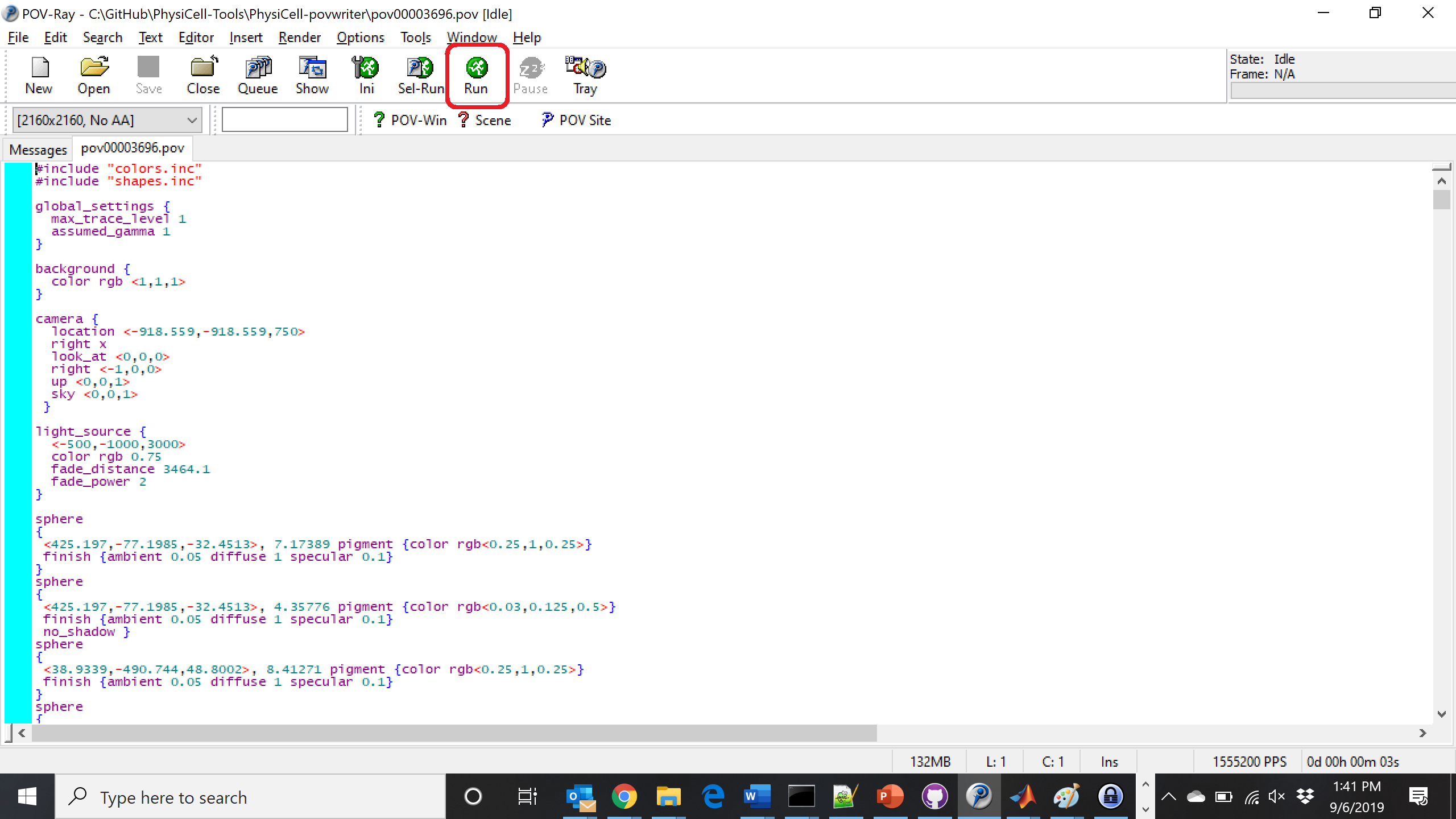
You can watch the image as it renders. The result should be a PNG file (named pov00003696.png) that looks like this:
Using command-line options to process multiple times (option #1)
Now, suppose we have more outputs to process. We still state most of the options in the XML file as above, but now we also supply a command-line argument in the form of start:interval:end. If you’re still in the povwriter project, note that we have some more sample data there. Let’s grab and process it:
physicell$ cd output physicell$ unzip more_samples.zip Archive: more_samples.zip inflating: output00000000_cells_physicell.mat inflating: output00000001_cells_physicell.mat inflating: output00000250_cells_physicell.mat inflating: output00000300_cells_physicell.mat inflating: output00000500_cells_physicell.mat inflating: output00000750_cells_physicell.mat inflating: output00001000_cells_physicell.mat inflating: output00001250_cells_physicell.mat inflating: output00001500_cells_physicell.mat inflating: output00001750_cells_physicell.mat inflating: output00002000_cells_physicell.mat inflating: output00002250_cells_physicell.mat inflating: output00002500_cells_physicell.mat inflating: output00002750_cells_physicell.mat inflating: output00003000_cells_physicell.mat inflating: output00003250_cells_physicell.mat inflating: output00003500_cells_physicell.mat inflating: output00003696_cells_physicell.mat physicell$ ls citation and license.txt more_samples.zip output00000000_cells_physicell.mat output00000001_cells_physicell.mat output00000250_cells_physicell.mat output00000300_cells_physicell.mat output00000500_cells_physicell.mat output00000750_cells_physicell.mat output00001000_cells_physicell.mat output00001250_cells_physicell.mat output00001500_cells_physicell.mat output00001750_cells_physicell.mat output00002000_cells_physicell.mat output00002250_cells_physicell.mat output00002500_cells_physicell.mat output00002750_cells_physicell.mat output00003000_cells_physicell.mat output00003250_cells_physicell.mat output00003500_cells_physicell.mat output00003696.xml output00003696_cells_physicell.mat
Let’s go back to the parent directory and run povwriter:
physicell$ ./povwriter 0:250:3500 povwriter version 1.0.0 ================================================================================ Copyright (c) Paul Macklin 2019, on behalf of the PhysiCell project OSI License: BSD-3-Clause (see LICENSE.txt) Usage: ================================================================================ povwriter : run povwriter with config file ./config/settings.xml povwriter FILENAME.xml : run povwriter with config file FILENAME.xml povwriter x:y:z : run povwriter on data in FOLDER with indices from x to y in incremenets of z Example: ./povwriter 0:2:10 processes files: ./FOLDER/FILEBASE00000000_physicell_cells.mat ./FOLDER/FILEBASE00000002_physicell_cells.mat ... ./FOLDER/FILEBASE00000010_physicell_cells.mat (See the config file to set FOLDER and FILEBASE) povwriter x1,...,xn : run povwriter on data in FOLDER with indices x1,...,xn Example: ./povwriter 1,3,17 processes files: ./FOLDER/FILEBASE00000001_physicell_cells.mat ./FOLDER/FILEBASE00000003_physicell_cells.mat ./FOLDER/FILEBASE00000017_physicell_cells.mat (Note that there are no spaces.) (See the config file to set FOLDER and FILEBASE) Code updates at https://github.com/PhysiCell-Tools/PhysiCell-povwriter Tutorial & documentation at http://MathCancer.org/blog/povwriter ================================================================================ Using config file ./config/povwriter-settings.xml ... Using standard coloring function ... Found 3 clipping planes ... Found 2 cell color definitions ... Matrix size: 32 x 18317 Processing file ./output/output00000000_cells_physicell.mat... Creating file pov00000000.pov for output ... Writing 18317 cells ... Processing file ./output/output00002000_cells_physicell.mat... Matrix size: 32 x 33551 Creating file pov00002000.pov for output ... Writing 33551 cells ... Processing file ./output/output00002500_cells_physicell.mat... Matrix size: 32 x 43440 Creating file pov00002500.pov for output ... Writing 43440 cells ... Processing file ./output/output00001500_cells_physicell.mat... Matrix size: 32 x 40267 Creating file pov00001500.pov for output ... Writing 40267 cells ... Processing file ./output/output00003000_cells_physicell.mat... Matrix size: 32 x 56659 Creating file pov00003000.pov for output ... Writing 56659 cells ... Processing file ./output/output00001000_cells_physicell.mat... Matrix size: 32 x 74057 Creating file pov00001000.pov for output ... Writing 74057 cells ... Processing file ./output/output00003500_cells_physicell.mat... Matrix size: 32 x 66791 Creating file pov00003500.pov for output ... Writing 66791 cells ... Processing file ./output/output00000500_cells_physicell.mat... Matrix size: 32 x 114316 Creating file pov00000500.pov for output ... Writing 114316 cells ... done! Processing file ./output/output00000250_cells_physicell.mat... Matrix size: 32 x 75352 Creating file pov00000250.pov for output ... Writing 75352 cells ... done! Processing file ./output/output00002250_cells_physicell.mat... Matrix size: 32 x 37959 Creating file pov00002250.pov for output ... Writing 37959 cells ... done! Processing file ./output/output00001750_cells_physicell.mat... Matrix size: 32 x 32358 Creating file pov00001750.pov for output ... Writing 32358 cells ... done! Processing file ./output/output00002750_cells_physicell.mat... Matrix size: 32 x 49658 Creating file pov00002750.pov for output ... Writing 49658 cells ... done! Processing file ./output/output00003250_cells_physicell.mat... Matrix size: 32 x 63546 Creating file pov00003250.pov for output ... Writing 63546 cells ... done! done! done! done! Processing file ./output/output00001250_cells_physicell.mat... Matrix size: 32 x 54771 Creating file pov00001250.pov for output ... Writing 54771 cells ... done! done! done! done! Processing file ./output/output00000750_cells_physicell.mat... Matrix size: 32 x 97642 Creating file pov00000750.pov for output ... Writing 97642 cells ... done! done! Done processing all 15 files!
Notice that the output appears a bit out of order. This is normal: povwriter is using 8 threads to process 8 files at the same time, and sending some output to the single screen. Since this is all happening simultaneously, it’s a bit jumbled (and non-sequential). Don’t panic. You should now have created pov00000000.pov, pov00000250.pov, … , pov00003500.pov.
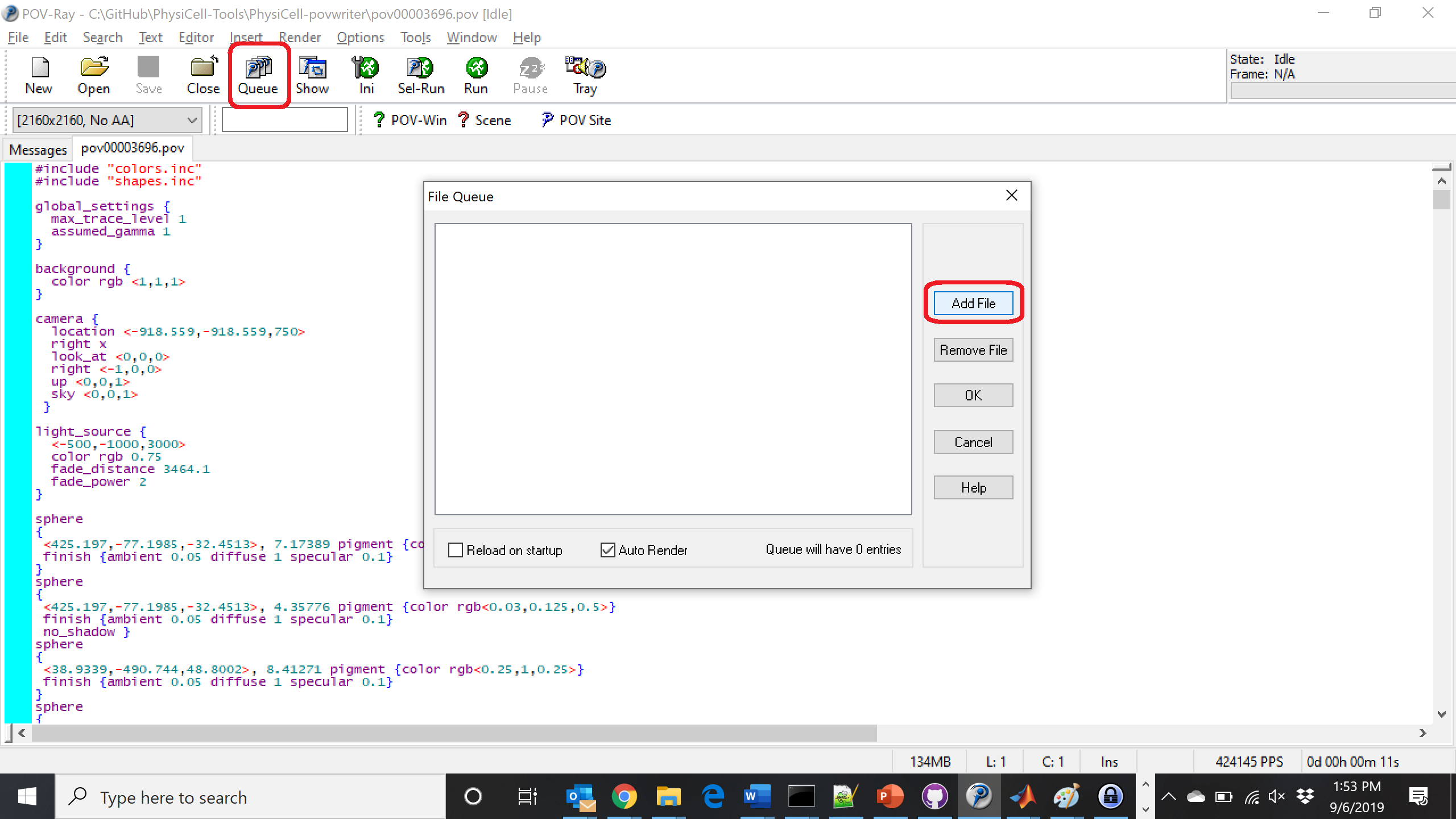
Now, go into POV-ray, and choose “queue.” Click “Add File” and select all 15 .pov files you just created:
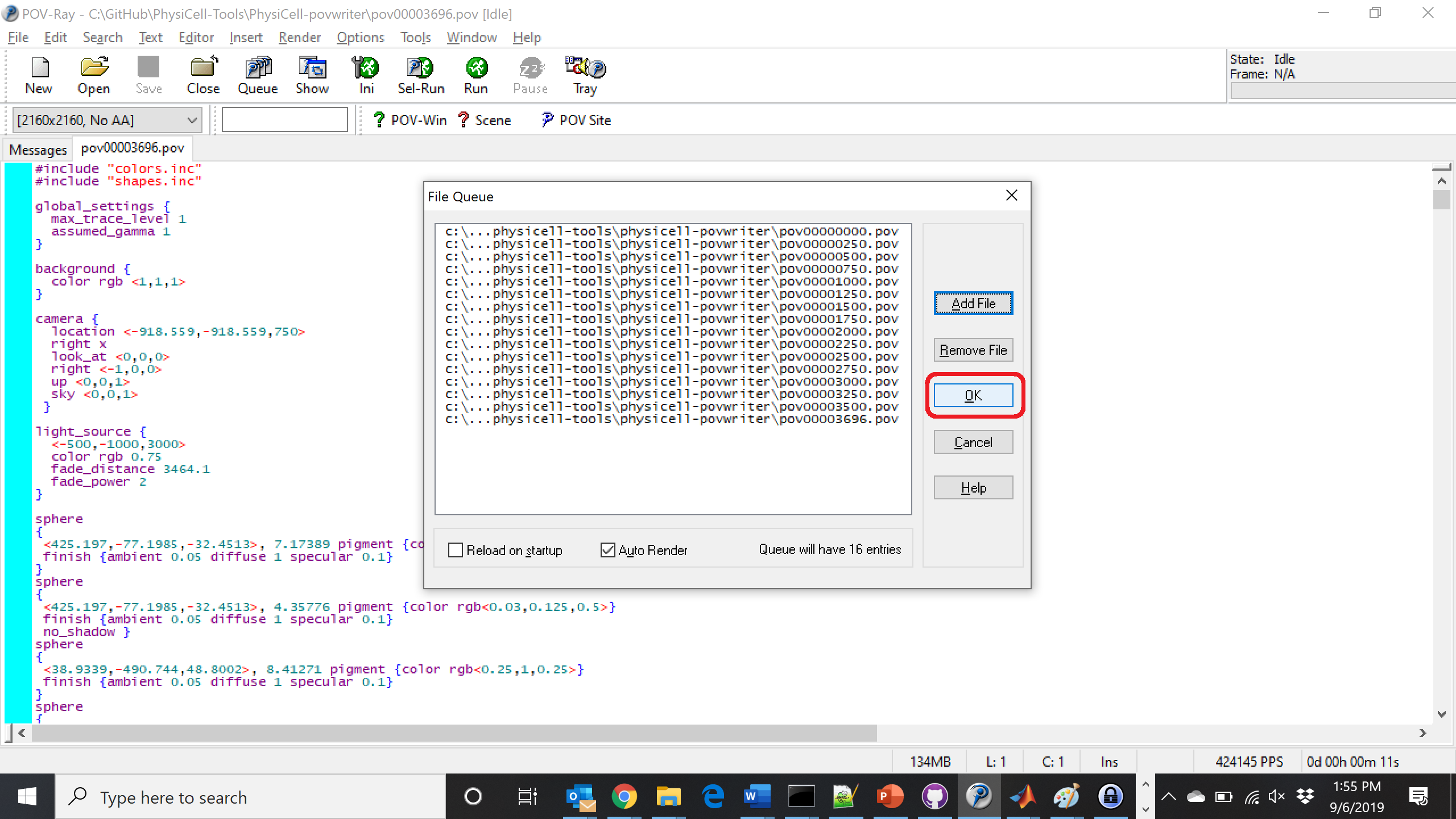
Hit “OK” to let it render all the povray files to create PNG files (pov00000000.png, … , pov00003500.png).
Using command-line options to process multiple times (option #2)
You can also give a list of indices. Here’s how we render time indices 250, 1000, and 2250:
physicell$ ./povwriter 250,1000,2250 povwriter version 1.0.0 ================================================================================ Copyright (c) Paul Macklin 2019, on behalf of the PhysiCell project OSI License: BSD-3-Clause (see LICENSE.txt) Usage: ================================================================================ povwriter : run povwriter with config file ./config/settings.xml povwriter FILENAME.xml : run povwriter with config file FILENAME.xml povwriter x:y:z : run povwriter on data in FOLDER with indices from x to y in incremenets of z Example: ./povwriter 0:2:10 processes files: ./FOLDER/FILEBASE00000000_physicell_cells.mat ./FOLDER/FILEBASE00000002_physicell_cells.mat ... ./FOLDER/FILEBASE00000010_physicell_cells.mat (See the config file to set FOLDER and FILEBASE) povwriter x1,...,xn : run povwriter on data in FOLDER with indices x1,...,xn Example: ./povwriter 1,3,17 processes files: ./FOLDER/FILEBASE00000001_physicell_cells.mat ./FOLDER/FILEBASE00000003_physicell_cells.mat ./FOLDER/FILEBASE00000017_physicell_cells.mat (Note that there are no spaces.) (See the config file to set FOLDER and FILEBASE) Code updates at https://github.com/PhysiCell-Tools/PhysiCell-povwriter Tutorial & documentation at http://MathCancer.org/blog/povwriter ================================================================================ Using config file ./config/povwriter-settings.xml ... Using standard coloring function ... Found 3 clipping planes ... Found 2 cell color definitions ... Processing file ./output/output00002250_cells_physicell.mat... Matrix size: 32 x 37959 Creating file pov00002250.pov for output ... Writing 37959 cells ... Processing file ./output/output00001000_cells_physicell.mat... Matrix size: 32 x 74057 Creating file pov00001000.pov for output ... Processing file ./output/output00000250_cells_physicell.mat... Matrix size: 32 x 75352 Writing 74057 cells ... Creating file pov00000250.pov for output ... Writing 75352 cells ... done! done! done! Done processing all 3 files!
This will create files pov00000250.pov, pov00001000.pov, and pov00002250.pov. Render them in POV-ray just as before.
Advanced options (at the source code level)
If you set use_standard_colors to false, povwriter uses the function my_pigment_and_finish_function (at the end of ./custom_modules/povwriter.cpp). Make sure that you set colors.cyto_pigment (RGB) and colors.nuclear_pigment (also RGB). The source file in povwriter has some hinting on how to write this. Note that the XML files saved by PhysiCell have a legend section that helps you do determine what is stored in each column of the matlab file.
Optional postprocessing
Image conversion / manipulation with ImageMagick
Suppose you want to convert the PNG files to JPEGs, and scale them down to 60% of original size. That’s very straightforward in ImageMagick:
physicell$ magick mogrify -format jpg -resize 60% pov*.png
Creating an animated GIF with ImageMagick
Suppose you want to create an animated GIF based on your images. I suggest first converting to JPG (see above) and then using ImageMagick again. Here, I’m adding a 20 ms delay between frames:
physicell$ magick convert -delay 20 *.jpg out.gif
Here’s the result:

Creating a compressed movie with Mencoder
Syntax coming later.
Closing thoughts and future work
In the future, we will probably allow more control over the clipping planes and a bit more debugging on how to handle planes that don’t pass through the origin. (First thoughts: we need to change how we use union and intersection commands in the POV-ray outputs.)
We should also look at adding some transparency for the cells. I’d prefer something like rgba (red-green-blue-alpha), but POV-ray uses filters and transmission, and we want to make sure to get it right.
Lastly, it would be nice to find a balance between the current very simple camera setup and better control.
Thanks for reading this PhysiCell Friday tutorial! Please do give PhysiCell at try (at http://PhysiCell.org) and read the method paper at PLoS Computational Biology.
Setting up the PhysiCell microenvironment with XML

As of release 1.6.0, users can define all the chemical substrates in the microenvironment with an XML configuration file. (These are stored by default in ./config/. The default parameter file is ./config/PhysiCell_settings.xml.) This should make it much easier to set up the microenvironment (previously required a lot of manual C++), as well as make it easier to change parameters and initial conditions.
In release 1.7.0, users gained finer grained control on Dirichlet conditions: individual Dirichlet conditions can be enabled or disabled for each individual diffusing substrate on each individual boundary. See details below.
This tutorial will show you the key techniques to use these features. (See the User_Guide for full documentation.) First, let’s create a barebones 2D project by populating the 2D template project. In a terminal shell in your root PhysiCell directory, do this:
make template2D
We will use this 2D project template for the remainder of the tutorial. We assume you already have a working copy of PhysiCell installed, version 1.6.0 or later. (If not, visit the PhysiCell tutorials to find installation instructions for your operating system.) You will need version 1.7.0 or later to control Dirichlet conditions on individual boundaries.
You can download the latest version of PhysiCell at:
- GitHub: https://github.com/MathCancer/PhysiCell/releases
- SourceForge: https://sourceforge.net/projects/physicell/files/latest/download
Microenvironment setup in the XML configuration file
Next, let’s look at the parameter file. In your text editor of choice, open up ./config/PhysiCell_settings.xml, and browse down to <microenvironment_setup>:
<microenvironment_setup> <variable name="oxygen" units="mmHg" ID="0"> <physical_parameter_set> <diffusion_coefficient units="micron^2/min">100000.0</diffusion_coefficient> <decay_rate units="1/min">0.1</decay_rate> </physical_parameter_set> <initial_condition units="mmHg">38.0</initial_condition> <Dirichlet_boundary_condition units="mmHg" enabled="true">38.0</Dirichlet_boundary_condition> </variable> <options> <calculate_gradients>false</calculate_gradients> <track_internalized_substrates_in_each_agent>false</track_internalized_substrates_in_each_agent> <!-- not yet supported --> <initial_condition type="matlab" enabled="false"> <filename>./config/initial.mat</filename> </initial_condition> <!-- not yet supported --> <dirichlet_nodes type="matlab" enabled="false"> <filename>./config/dirichlet.mat</filename> </dirichlet_nodes> </options> </microenvironment_setup>
Notice a few trends:
- The <variable> XML element (tag) is used to define a chemical substrate in the microenvironment. The attributes say that it is named oxygen, and the units of measurement are mmHg. Notice also that the ID is 0: this unique integer identifier helps for finding and accessing the substrate within your PhysiCell project. Make sure your first substrate ID is 0, since C++ starts indexing at 0.
- Within the <variable> block, we set the properties of this substrate:
- <diffusion_coefficient> sets the (uniform) diffusion constant for the substrate.
- <decay_rate> is the substrate’s background decay rate.
- <initial_condition> is the value the substrate will be (uniformly) initialized to throughout the domain.
- <Dirichlet_boundary_condition> is the value the substrate will be set to along the outer computational boundary throughout the simulation, if you set enabled=true. If enabled=false, then PhysiCell (via BioFVM) will use Neumann (zero flux) conditions for that substrate.
- The <options> element helps configure other simulation behaviors:
- Use <calculate_gradients> to control whether PhysiCell computes all chemical gradients at each time step. Set this to true to enable accurate gradients (e.g., for chemotaxis).
- Use <track_internalized_substrates_in_each_agent> to enable or disable the PhysiCell feature of actively tracking the total amount of internalized substrates in each individual agent. Set this to true to enable the feature.
- <initial_condition> is reserved for a future release where we can specify non-uniform initial conditions as an external file (e.g., a CSV or Matlab file). This is not yet supported.
- <dirichlet_nodes> is reserved for a future release where we can specify Dirchlet nodes at any location in the simulation domain with an external file. This will be useful for irregular domains, but it is not yet implemented.
Note that PhysiCell does not convert units. The units attributes are helpful for clarity between users and developers, to ensure that you have worked in consistent length and time units. By default, PhysiCell uses minutes for all time units, and microns for all spatial units.
Changing an existing substrate
Let’s modify the oxygen variable to do the following:
- Change the diffusion coefficient to 120000 \(\mu\mathrm{m}^2 / \mathrm{min}\)
- Change the initial condition to 40 mmHg
- Change the oxygen Dirichlet boundary condition to 42.7 mmHg
- Enable gradient calculations
If you modify the appropriate fields in the <microenvironment_setup> block, it should look like this:
<microenvironment_setup> <variable name="oxygen" units="mmHg" ID="0"> <physical_parameter_set> <diffusion_coefficient units="micron^2/min">120000.0</diffusion_coefficient> <decay_rate units="1/min">0.1</decay_rate> </physical_parameter_set> <initial_condition units="mmHg">40.0</initial_condition> <Dirichlet_boundary_condition units="mmHg" enabled="true">42.7</Dirichlet_boundary_condition> </variable> <options> <calculate_gradients>true</calculate_gradients> <track_internalized_substrates_in_each_agent>false</track_internalized_substrates_in_each_agent> <!-- not yet supported --> <initial_condition type="matlab" enabled="false"> <filename>./config/initial.mat</filename> </initial_condition> <!-- not yet supported --> <dirichlet_nodes type="matlab" enabled="false"> <filename>./config/dirichlet.mat</filename> </dirichlet_nodes> </options> </microenvironment_setup>
Adding a new diffusing substrate
Let’s add a new dimensionless substrate glucose with the following:
- Diffusion coefficient is 18000 \(\mu\mathrm{m}^2 / \mathrm{min}\)
- No decay rate
- The initial condition is 1 (dimensionless)
- Neumann (no flux) boundary conditions
To add the new variable, I suggest copying an existing variable (in this case, oxygen) and modifying to:
- change the name and units throughout
- increase the ID by one
- write in the appropriate initial and boundary conditions
If you modify the appropriate fields in the <microenvironment_setup> block, it should look like this:
<microenvironment_setup> <variable name="oxygen" units="mmHg" ID="0"> <physical_parameter_set> <diffusion_coefficient units="micron^2/min">120000.0</diffusion_coefficient> <decay_rate units="1/min">0.1</decay_rate> </physical_parameter_set> <initial_condition units="mmHg">40.0</initial_condition> <Dirichlet_boundary_condition units="mmHg" enabled="true">42.7</Dirichlet_boundary_condition> </variable> <variable name="glucose" units="dimensionless" ID="1"> <physical_parameter_set> <diffusion_coefficient units="micron^2/min">18000.0</diffusion_coefficient> <decay_rate units="1/min">0.0</decay_rate> </physical_parameter_set> <initial_condition units="dimensionless">1</initial_condition> <Dirichlet_boundary_condition units="dimensionless" enabled="false">0</Dirichlet_boundary_condition> </variable> <options> <calculate_gradients>true</calculate_gradients> <track_internalized_substrates_in_each_agent>false</track_internalized_substrates_in_each_agent> <!-- not yet supported --> <initial_condition type="matlab" enabled="false"> <filename>./config/initial.mat</filename> </initial_condition> <!-- not yet supported --> <dirichlet_nodes type="matlab" enabled="false"> <filename>./config/dirichlet.mat</filename> </dirichlet_nodes> </options> </microenvironment_setup>
Controlling Dirichlet conditions on individual boundaries
In Version 1.7.0, we introduced the ability to control the Dirichlet conditions for each individual boundary for each substrate. The examples above apply (enable) or disable the same condition on each boundary with the same boundary value.
Suppose that we want to set glucose so that the Dirichlet condition is enabled on the bottom z boundary (with value 1) and the left and right x boundaries (with value 0.5) and disabled on all other boundaries. We modify the variable block by adding the optional Dirichlet_options block:
<variable name="glucose" units="dimensionless" ID="1"> <physical_parameter_set> <diffusion_coefficient units="micron^2/min">18000.0</diffusion_coefficient> <decay_rate units="1/min">0.0</decay_rate> </physical_parameter_set> <initial_condition units="dimensionless">1</initial_condition> <Dirichlet_boundary_condition units="dimensionless" enabled="true">0</Dirichlet_boundary_condition> <Dirichlet_options> <boundary_value ID="xmin" enabled="true">0.5</boundary_value> <boundary_value ID="xmax" enabled="true">0.5</boundary_value> <boundary_value ID="ymin" enabled="false">0.5</boundary_value> <boundary_value ID="ymin" enabled="false">0.5</boundary_value> <boundary_value ID="zmin" enabled="true">1.0</boundary_value> <boundary_value ID="zmax" enabled="false">0.5</boundary_value> </Dirichlet_options> </variable>
Notice a few things:
- The Dirichlet_boundary_condition element has its enabled attribute set to true
- The Dirichlet condition is set under any individual boundary with a boundary_value element.
- The ID attribute indicates which boundary is being specified.
- The enabled attribute allows the individual boundary to be enabled (with value given by the element’s value) or disabled (applying a Neumann or no-flux condition for this substrate at this boundary).
- Any individual boundary indicated by a boundary_value element supersedes the value given by Dirichlet_boundary_condition for this boundary.
Closing thoughts and future work
In the future, we plan to develop more of the options to allow users to set set the initial conditions externally and import them (via an external file), and to allow them to set up more complex domains by importing Dirichlet nodes.
More broadly, we are working to push more model specification from raw C++ to imported XML. It is our hope that this will vastly simplify model development, facilitate creation of graphical model editing tools, and ultimately broaden the class of developers who can use and contribute to PhysiCell. Thanks for giving it a try!
User parameters in PhysiCell
As of release 1.4.0, users can add any number of Boolean, integer, double, and string parameters to an XML configuration file. (These are stored by default in ./config/. The default parameter file is ./config/PhysiCell_settings.xml.) These parameters are automatically parsed into a parameters data structure, and accessible throughout a PhysiCell project.
This tutorial will show you the key techniques to use these features. (See the User_Guide for full documentation.) First, let’s create a barebones 2D project by populating the 2D template project. In a terminal shell in your root PhysiCell directory, do this:
make template2D
We will use this 2D project template for the remainder of the tutorial. We assume you already have a working copy of PhysiCell installed, version 1.4.0 or later. (If not, visit the PhysiCell tutorials to find installation instructions for your operating system.)
User parameters in the XML configuration file
Next, let’s look at the parameter file. In your text editor of choice, open up ./config/PhysiCell_settings.xml, and browse down to <user_parameters>, which will have some sample parameters from the 2D template project.
<user_parameters> <random_seed type="int" units="dimensionless">0</random_seed> <!-- example parameters from the template --> <!-- motile cell type parameters --> <motile_cell_persistence_time type="double" units="min">15</motile_cell_persistence_time> <motile_cell_migration_speed type="double" units="micron/min">0.5</motile_cell_migration_speed> <motile_cell_relative_adhesion type="double" units="dimensionless">0.05</motile_cell_relative_adhesion> <motile_cell_apoptosis_rate type="double" units="1/min">0.0</motile_cell_apoptosis_rate> <motile_cell_relative_cycle_entry_rate type="double" units="dimensionless">0.1</motile_cell_relative_cycle_entry_rate> </user_parameters>
Notice a few trends:
- Each XML element (tag) under <user_parameters> is a user parameter, whose name is the element name.
- Each variable requires an attribute named “type”, with one of the following four values:
- bool for a Boolean parameter
- int for an integer parameter
- double for a double (floating point) parameter
- string for text string parameter
While we do not encourage it, if no valid type is supplied, PhysiCell will attempt to interpret the parameter as a double.
- Each variable here has an (optional) attribute “units”. PhysiCell does not convert units, but these are helpful for clarity between users and developers. By default, PhysiCell uses minutes for all time units, and microns for all spatial units.
- Then, between the tags, you list the value of your parameter.
Let’s add the following parameters to the configuration file:
- A string parameter called motile_color that sets the color of the motile_cell type in SVG outputs. Please refer to the User Guide (in the documentation folder) for more information on allowed color formats, including rgb values and named colors. Let’s use the value darkorange.
- A double parameter called base_cycle_entry_rate that will give the rate of entry to the S cycle phase from the G1 phase for the default cell type in the code. Let’s use a ridiculously high value of 0.01 min-1.
- A double parameter called base_apoptosis_rate for the default cell type. Let’s set the value at 1e-7 min-1.
- A double parameter that sets the (relative) maximum cell-cell adhesion sensing distance, relative to the cell’s radius. Let’s set it at 2.5 (dimensionless). (The default is 1.25.)
- A bool parameter that enables or disables placing a single motile cell in the initial setup. Let’s set it at true.
If you edit the <user_parameters> to include these, it should look like this:
<user_parameters> <random_seed type="int" units="dimensionless">0</random_seed> <!-- example parameters from the template --> <!-- motile cell type parameters --> <motile_cell_persistence_time type="double" units="min">15</motile_cell_persistence_time> <motile_cell_migration_speed type="double" units="micron/min">0.5</motile_cell_migration_speed> <motile_cell_relative_adhesion type="double" units="dimensionless">0.05</motile_cell_relative_adhesion> <motile_cell_apoptosis_rate type="double" units="1/min">0.0</motile_cell_apoptosis_rate> <motile_cell_relative_cycle_entry_rate type="double" units="dimensionless">0.1</motile_cell_relative_cycle_entry_rate> <!-- for the tutorial --> <motile_color type="string" units="dimensionless">darkorange</motile_color> <base_cycle_entry_rate type="double" units="1/min">0.01</base_cycle_entry_rate> <base_apoptosis_rate type="double" units="1/min">1e-7</base_apoptosis_rate> <base_cell_adhesion_distance type="double" units="dimensionless">2.5</base_cell_adhesion_distance> <include_motile_cell type="bool" units="dimensionless">true</include_motile_cell> </user_parameters>
Viewing the loaded parameters
Let’s compile and run the project.
make ./project2D
At the beginning of the simulation, PhysiCell parses the <user_parameters> block into a global data structure called parameters, with sub-parts bools, ints, doubles, and strings. It displays these loaded parameters at the start of the simulation. Here’s what it looks like:
shell$ ./project2D Using config file ./config/PhysiCell_settings.xml ... User parameters in XML config file: Bool parameters:: include_motile_cell: 1 [dimensionless] Int parameters:: random_seed: 0 [dimensionless] Double parameters:: motile_cell_persistence_time: 15 [min] motile_cell_migration_speed: 0.5 [micron/min] motile_cell_relative_adhesion: 0.05 [dimensionless] motile_cell_apoptosis_rate: 0 [1/min] motile_cell_relative_cycle_entry_rate: 0.1 [dimensionless] base_cycle_entry_rate: 0.01 [1/min] base_apoptosis_rate: 1e-007 [1/min] base_cell_adhesion_distance: 2.5 [dimensionless] String parameters:: motile_color: darkorange [dimensionless]
Getting parameter values
Within a PhysiCell project, you can access the value of any parameter by either its index or its name, so long as you know its type. Here’s an example of accessing the base_cell_adhesion_distance by its name:
/* this directly accesses the value of the parameter */
double temp = parameters.doubles( "base_cell_adhesion_distance" );
std::cout << temp << std::endl;
/* this streams a formatted output including the parameter name and units */
std::cout << parameters.doubles[ "base_cell_adhesion_distance" ] << std::endl;
std::cout << parameters.doubles["base_cell_adhesion_distance"].name << " "
<< parameters.doubles["base_cell_adhesion_distance"].value << " "
<< parameters.doubles["base_cell_adhesion_distance"].units << std::endl;
Notice that accessing by () gets the value of the parameter in a user-friendly way, whereas accessing by [] gets the entire parameter, including its name, value, and units.
You can more efficiently access the parameter by first finding its integer index, and accessing by index:
/* this directly accesses the value of the parameter */
int my_index = parameters.doubles.find_index( "base_cell_adhesion_distance" );
double temp = parameters.doubles( my_index );
std::cout << temp << std::endl;
/* this streams a formatted output including the parameter name and units */
std::cout << parameters.doubles[ my_index ] << std::endl;
std::cout << parameters.doubles[ my_index ].name << " "
<< parameters.doubles[ my_index ].value << " "
<< parameters.doubles[ my_index ].units << std::endl;
Similarly, we can access string and Boolean parameters. For example:
if( parameters.bools("include_motile_cell") == true )
{ std::cout << "I shall include a motile cell." << std::endl; }
int rand_ind = parameters.ints.find_index( "random_seed" );
std::cout << parameters.ints[rand_ind].name << " is at index " << rand_ind << std::endl;
std::cout << "We'll use this nice color: " << parameters.strings( "motile_color" );
Using the parameters in custom functions
Let’s use these new parameters when setting up the parameter values of the simulation. For this project, all custom code is in ./custom_modules/custom.cpp. Open that source file in your favorite text editor. Look for the function called “create_cell_types“. In the code snipped below, we access the parameter values to set the appropriate parameters in the default cell definition, rather than hard-coding them.
// add custom data here, if any
/* for the tutorial */
cell_defaults.phenotype.cycle.data.transition_rate(G0G1_index,S_index) =
parameters.doubles("base_cycle_entry_rate");
cell_defaults.phenotype.death.rates[apoptosis_model_index] =
parameters.doubles("base_apoptosis_rate");
cell_defaults.phenotype.mechanics.set_relative_maximum_adhesion_distance(
parameters.doubles("base_cell_adhesion_distance") );
Next, let’s change the tissue setup (“setup_tissue“) to check our Boolean variable before placing the initial motile cell.
// now create a motile cell
/* remove this conditional for the normal project */
if( parameters.bools("include_motile_cell") == true )
{
pC = create_cell( motile_cell );
pC->assign_position( 15.0, -18.0, 0.0 );
}
Lastly, let’s make use of the string parameter to change the plotting. Search for my_coloring_function and edit the source file to use the new color:
// if the cell is motile and not dead, paint it black
static std::string motile_color = parameters.strings( "motile_color" ); // tutorial
if( pCell->phenotype.death.dead == false && pCell->type == 1 )
{
output[0] = motile_color;
output[2] = motile_color;
}
Notice the static here: We intend to call this function many, many times. For performance reasons, we don’t want to declare a string, instantiate it with motile_color, pass it to parameters.strings(), and then deallocate it once done. Instead, we store the search statically within the function, so that all future function calls will have access to that search result.
And that’s it! Compile your code, and give it a go.
make ./project2D
This should create a lot of data in the ./output directory, including SVG files that color motile cells as darkorange, like this one below.
Now that this project is parsing the XML file to get parameter values, we don’t need to recompile to change a model parameter. For example, change motile_color to mediumpurple, set motile_cell_migration_speed to 0.25, and set motile_cell_relative_cycle_entry_rate to 2.0. Rerun the code (without compiling):
./project2D
And let’s look at the change in the final SVG output (output00000120.svg):

More notes on configuration files
You may notice other sections in the XML configuration file. I encourage you to explore them, but the meanings should be evident: you can set the computational domain size, the number of threads (for OpenMP parallelization), and how frequently (and where) data are stored. In future PhysiCell releases, we will continue adding more and more options to these XML files to simplify setup and configuration of PhysiCell models.
ParaView for PhysiCell – Part 1
In this tutorial, we discuss the topic of visualizing data that is generated by PhysiCell. Specifically, we discuss the visualization of cells. In a later post, we’ll discuss options for visualizing the microenvironment. For 2-D models, PhysiCell generates Scalable Vector Graphics (SVG) files that depict cells’ positions, sizes (volumes), and colors (virtual pathology). Obviously, visualizing cells from 3-D models is more challenging. (Note: SVG files are also generated for 3-D models; however, they capture only the cells that intersect the Z=0 plane). Until now, we have only discussed a couple of applications for visualizing 3-D data from PhysiCell: MATLAB (or Octave) and POV-Ray. In this post, we describe ParaView: an open source, data analysis and visualization application from Kitware. ParaView can be used to visualize a wide variety of scientific data, as depicted on their gallery page.
Preliminary steps
Before we get started, just a reminder – if you have any problems or questions, please join our mailing list (physicell-users@googlegroups.com) to get help. In preparation for using the customized PhysiCell data reader in ParaView, you will need to have a specific Python module, scipy, installed. Python will be a useful language for other PhysiCell data analysis and visualization tasks too, so having it installed on your computer will come in handy later, beyond using ParaView. The confusion of installing/using Python (and the scipy module) for ParaView is due to multiple factors:
- you may or may not have Administrator permission on your computer,
- there are different versions of Python, including the major version confusion – 2 vs. 3,
- there are different distributions of Python, and
- ParaView comes with its own built-in Python (version 2), but it isn’t easily extensible.
Before we get operating system specific, we just want to point out that it is possible to have multiple versions and/or distributions of Python on your computer. Unfortunately, there is no guarantee that you can mix modules of one with another. This is especially true for one popular Python distribution, Anaconda, and any other distribution.
We now provide some detailed instructions for the primary operating systems. In the sections that follow, we assume you have Admin permission on your computer. If you do not and you need to install Python + scipy as a standard user, see Appendix A at the end.
Windows
Windows does not come with Python, by default. Therefore, you will need to download/install it from python.org – get the latest 2.x version – currently https://www.python.org/downloads/release/python-2714/.
During the installation process, you will be asked if you want to install for all users or just yourself. That is up to you.
You’ll have the option of changing the default installation directory. We recommend keeping the default: C:\Python27.

Finally, you will have the choice of having this python executable be your default. That is up to you. If you have another Python distribution installed that you want to keep as your default, then you should leave this choice unchecked, i.e. leave the “X”. But if you do want to use this one as your default, select “Add python.exe to Path”:

After completing the Python 2.7 installation, open a Command Prompt shell and run (or if you selected to use this python.exe as your default in the above step, you can just use ‘python’ instead of specifying the full path):
c:\python27\python.exe -m pip install scipy
This will download and install the scipy module which is what our PhysiCell data reader uses. You can verify that it got installed by running python and trying to import it:
c:\>python27\python.exe Python 2.7.14 (v2.7.14:84471935ed, Sep 16 2017, 20:25:58) [MSC v.1500 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> import scipy >>> quit()
OSX and Linux
Both OSX and Linux come with a system-level version of Python pre-installed (/usr/bin/python). Regardless of whether you have installed additional versions of Python, you will want to make sure the pre-installed version has the scipy module. OSX should already have it. However, Linux will not and you will need to install it via:
/usr/bin/python -m pip install scipy
You can test if scipy is accessible by simply trying to import it:
/usr/bin/python ... >>> import scipy >>> quit()
Installing ParaView
After you have successfully installed Python + scipy, download and install the (binary) ParaView application for your particular platform. The current, stable version is 5.4.1.
Windows
Assuming you have Admin permission, download/install ParaView-5.4.1-Qt5-OpenGL2-Windows-64bit.exe. If you do not have Admin permission, see Appendix A.
OSX or Linux
On OSX, assuming you have Admin permissions, download/install ParaView-5.4.1-Qt5-OpenGL2-MPI-OSX10.8-64bit.dmg. If you do not have Admin permission, see Appendix A.
On Linux, download ParaView-5.4.1-Qt5-OpenGL2-MPI-Linux-64bit.tar.gz and uncompress it into an appropriate directory. For example, if you want to make ParaView available to everyone, you may want to uncompress it into /usr/local. If you only want to make it available for your personal use, see Appendix A.
Running ParaView
Before starting the ParaView application, you can set an environment variable, PHYSICELL_DATA, to be the full path to the directory where the PhysiCell data can be found. This will make it easier for the custom data reader (a Python script) in the ParaView pipeline to find the data. For example, in the next section we provide a link to some sample PhysiCell data. If you simply uncompress that zip archive into your Downloads directory, then (on Linux/OSX bash) you could:
$ export PHYSICELL_DATA=/path-to-your-home-dir/Downloads
(this Windows tutorial, while aimed at editing your PATH, will also help you find the environment variables setting).
If you choose not to set the PHYSICELL_DATA environment variable, the custom data reader will look in your user Downloads directory. Alternatively, you can simply edit the ParaView custom data reader Python script to point to your data directory (and then you would probably want to File -> Save State).
NOTE: if you are using OSX and want to use the PHYSICELL_DATA environment variable, you should start the ParaView application from the Terminal, e.g. $ /Applications/ParaView-5.4.1.app/Contents/MacOS/paraview &
Finally, go ahead and start the ParaView application. You should see a blank GUI (Figure 1). Don’t be frightened by the complexity of the GUI – yes, there are several widgets, but we will walk you down a minimal path to help you visualize PhysiCell cell data. Of course you have access to all of ParaView’s documentation – the Getting Started, Guide, and Tutorial under the Help menu are a good place to start. In addition to the downloadable (.pdf) documentation, there is also in-depth information online: https://www.paraview.org/Wiki/ParaView
![]()
Figure 1. The ParaView application
Note: the 3-D axis in the lower-left corner of the RenderView does not represent the origin. It is just a reference axis to provide 3-D orientation.
Before you get started with examples, you should open ParaView’s Settings (Preferences), select the General tab, and make sure “Auto Apply” is checked. This will avoid the need to manually “Apply” changes you make to an object’s properties.
Cancer immunity 3D example
We will use sample output data from the cancer_immune_3D project – one of the sample projects bundled with PhysiCell. You can refer to the PhysiCell Quickstart guide if you want to actually compile and run that project. But to simplify this tutorial, we provide sample data (a single time step) from that project, at:
https://sourceforge.net/projects/physicell/files/Tutorials/MultiCellDS/3D_PhysiCell_matlab_sample.zip/download
After you extract the files from this .zip, the file of interest for this tutorial is called output00003696_cells_physicell.mat. (And remember, as discussed above, to set the PHYSICELL_DATA environment variable to point to the directory where you extracted the files).
Additionally, for this tutorial, you’ll need some predefined ParaView state files (*.pvsm). A state file is just what it sounds like – it saves the entire state of a ParaView session so that you can easily re-use it. For this tutorial, we have provided the following state files to help you get started:
- physicell_glyphs.pvsm – render cells as simple vertex glyphs
- physicell_z0slice.pvsm – render the intersection of spherical glyphs with the Z=0 plane
- physicell_3clip_planes_ospray.pvsm – OSPRay renderer with 3 clipping planes
- physicell_cells_animate.pvsm – demonstrate how to do animation
Download them here: physicell_paraview_states.zip
Figure 2 is the SVG image from the sample data. It depicts the (3-D) cells that intersect the Z=0 plane.

Figure 2. snapshot00003696.svg generated by PhysiCell
Reading PhysiCell (cell) data
One way that ParaView offers extensibility is via Python scripts. To make it easier to read data generated by PhysiCell, we provide users with a “Programmable Source” that will read and process data in a file. In the ParaView screen-captured figures below, the Programmable Source (“PhysiCellReader_cells”) will be the very first module in the pipeline.
For this exercise, you can File->LoadState and select the physicell_glyphs.pvsm file that you downloaded above. Assuming you previously copied the output00003696_cells_physicell.mat sample data file into one of the default directories as described above, it should display the results in Figure 3. (Otherwise, you will likely see an error message appear, in which case see Appendix B). These are the simplest (and fastest) glyphs to represent PhysiCell cells. They are known as 2-D Vertex glyphs, although the 2-D is misleading since they are rendered in 3-space. At this point, you can interact – rotate, zoom, pan, with the visualization (rf. Sect. 4.4.2 in the ParaViewGuide-5.4.0 for an explanation of the controls, but basically: left-mouse button hold while moving cursor to rotate; Ctl-left-mouse for zoom; Ctl-Shift-left-mouse to pan).
For this particular ParaView state file, we use the following code to assign colors to cells (Note: the PhysiCell code in /custom_modules creates the SVG file using colors based on cells’ neighbor information. This information is not saved in the .mat output files, therefore we cannot faithfully reproduce SVG cell colors here):
# The following lines assign an integer to represent
# a color, defined in a Color Map.
sval = 0 # immune cells are yellow?
if val[5,idx] == 1: # [5]=cell_type
sval = 1 # lime green
if (val[6,idx] == 6) or (val[6,idx] == 7):
sval = 0
if val[7,idx] == 100: # [7]=current_phase
sval = 3 # apoptotic: red
if val[7,idx] > 100 and val[7,idx] < 104:
sval = 2 # necrotic: brownish
Figure 3. Glyphs as vertices

Figure 4. Glyphs as spheres
The next exercise is a simple extension of the previous. We want to add a slice to our pipeline that will intersect the cells (spherical glyphs). Assuming the slice is the Z=0 plane, this will approximate the SVG in Figure 2. So, select Edit->ResetSession to start from scratch, then File->LoadState and select the physicell_z0slice.pvsm file. Note that the “Glyph1” node in the pipeline is invisible (its “eyeball” is toggled off). If you make it visible (select the eyeball), you will essentially reproduce Figure 4. But for this exercise, we want Glyph1 to be invisible and Slice1 visible. If you select Slice1 (its green box) in the pipeline, you can select its Properties tab (at the top) to see all its properties. Of particular interest is the “Show Plane” checkbox at the top.
![]()
If this is checked on, you can interactively translate the plane along its normal, as well as select and rotate the normal itself. Try it! You can also “hardcode” the slice plane parameters in its properties panel.

Figure 5. Z=0 slice through the spherical glyphs (approximate SVG slice)
Our final exercise with the sample dataset is to visualize cells using a higher quality renderer in ParaView known as OSPRay. So, as before, Edit->ResetSession to start from scratch, then File->LoadState and select the physicell_3clip_planes_ospray.pvsm file. This will create a pipeline that has 3 clipping planes aligned such that an octant of our spheroidal cell cluster is clipped away, letting us peer into its core (Figure 6). As with the previous slice plane, you can interactively reposition one or more of the clipping planes here.
Note: One (temporary) downside of using the OSPRay renderer is that cells (spheres) cannot be arbitrarily scaled in size. This will be fixed in a future release of ParaView. For now, we get around that by shrinking the distance of each cell from the origin. Obviously this is not a perfect solution, but for cells that are sort of clustered around the origin, it offers a decent approximation. We mention this 1) to disclose the inaccuracy, and 2) in case you look at the data ranges in the “Information” view/tab and notice they are not reflecting the domain of your simulation.
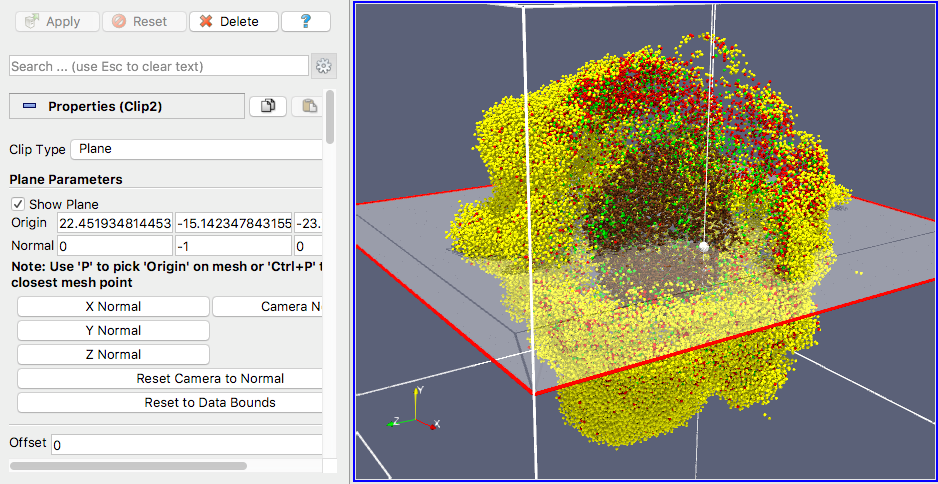
Figure 6. OSPRay-rendered cells, showing 1 of 3 interactive clipping planes
Animation in Time
At some point, you’ll want to see the dynamics of your simulation. This is where ParaView’s animation functionality comes in handy. It provides an easy way to let you render all (or a subset) of your PhysiCell output files, control the animation, and also save images (as .png files).
For this exercise, you will obviously want to have generated multiple output files from a PhysiCell project. Once you have those, e.g. from the cancer_immune_3D project, you can File->LoadState and select the physicell_cells_animate.pvsm file. This will show the following pipeline:

If you select the PhysiCellReader_cells (green box; leave its “eye” icon deselected) and click on the Properties tab, you will have access to the Script(RequestInformation) (you may need to click the “gear” icon next to the Properties tab Search bar to “Toggle advanced properties” to see this script):
In there, you will see the lines:
timeSteps = range(1,20,1) # (start, stop+1, step) #timeSteps = range(100,801,50) # (start, stop+1 [, step])
You’ll want to edit the first line, specifying your desired start, stop, and (optionally) step values for your files’ numeric suffixes. We happened to use the second timeSteps line (currently commented out with the ‘#’) for data from our simulation, which resulted in 15 time steps (0-14) for the time values: 100,150,200,…800. Pressing the Play (center) button of the animation icons would animate those frames:
![]()
When you like what you see, you can select File->SaveAnimation to save the images. After you provide some minimal information for those images, e.g., resolution and filename prefix, press “OK” and you will see a horizontal progress bar being updated below the render window. After the animation images are generated, you can use your favorite image processing and movie generation tools to post-process them. In Figure 7, we used ImageMagick’s montage command to arrange the 15 images from a cancer_immune_3D simulation. And for generating a movie file, take a look at mplayer/mencoder as one open source option.
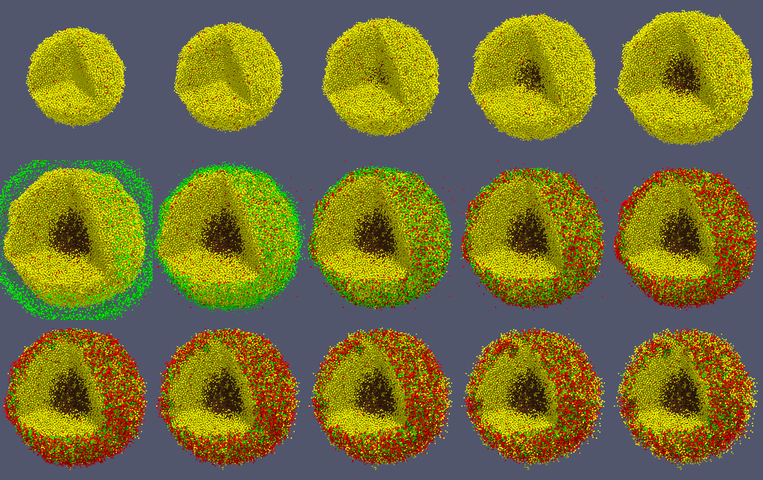
Figure 7. Images from cancer_immune_3D
Further Help
For questions specific to PhysiCell, have a look at our User Guide and join our mailing list to ask questions. For ParaView, have a look at their User Guide and join the ParaView mailing list to ask questions.
Thanks!
In closing, we would like to thank Kitware for their terrific open source software and the ParaView community (especially David DeMarle and Utkarsh Ayachit) for being so helpful answering questions and providing insight. We were honored that some of our early results got headlined on Kitware’s home page!
Appendix A: Installing without Admin permission
If you do not have Admin permission on your computer, we provide instructions for installing Python + scipy and ParaView using alternative approaches.
Windows
To install Python on Windows, without Admin permission, run the msiexec command on the .msi Python installer that you downloaded, specifying a (non-system) directory in which it should be installed via the targetdir keyword. After that completes, Python will be installed; however, the python command will not be in your PATH, i.e., it will not be globally accessible.
C:\Users\sue\Downloads>msiexec /a python-2.7.14.amd64.msi /qb targetdir=c:\py27 C:\Users\sue\Downloads>python 'python' is not recognized as an internal or external command, operable program or batch file. C:\Users\sue\Downloads>cd c:\py27 c:\py27>.\python.exe Python 2.7.14 (v2.7.14:84471935ed, Sep 16 2017, 20:25:58) [MSC v.1500 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>>
Finally, download ParaView-5.4.1-Qt5-OpenGL2-Windows-64bit.zip and extract its contents into a permissible directory, e.g. under your home folder: C:\Users\sue\ParaView-5.4.1-Qt5-OpenGL2-Windows-64bit\
Then, in ParaView, using the Tools menu, open the Python Shell, and see if you can import scipy via:
>>> sys.path.insert(0,'c:\py27\Lib\site-packages') >>> import scipy
Before proceeding with the tutorial using the PhysiCell state files, you will want to open ParaView’s Settings and check (toggle on) the “Auto Apply” property in the General settings tab.
OSX
OSX comes with a system Python pre-installed. And, at least with fairly recent versions of OSX, it comes with the scipy module also. You can test to see if that is the case on your system:
/usr/bin/python >>> import scipy
To install ParaView, download a .pkg, not a .dmg, e.g. ParaView-5.4.1-Qt5-OpenGL2-MPI-OSX10.8-64bit.pkg. Then expand that .pkg contents into a permissible directory and untar its “Payload” which contains the actual paraview executable that you can open/run:
cd ~/Downloads pkgutil --expand ParaView-5.4.1-Qt5-OpenGL2-MPI-OSX10.8-64bit.pkg ~/paraview cd ~/paraview tar -xvf Payload open Contents/MacOS/paraview
Linux
Like OSX, Linux also comes with a system Python pre-installed. However, it does not come with the scipy module. To install the scipy Python module, run:
/usr/bin/python -m pip install scipy --user
To install and run ParaView, download the .tar.gz file, e.g. ParaView-5.4.1-Qt5-OpenGL2-MPI-Linux-64bit.tar.gz and uncompress it into a permissible directory. For example, from your home directory (after downloading):
mv ~/Downloads/ParaView-5.4.1-Qt5-OpenGL2-MPI-Linux-64bit.tar.gz . tar -xvzf ParaView-5.4.1-Qt5-OpenGL2-MPI-Linux-64bit.tar.gz cd ParaView-5.4.1-Qt5-OpenGL2-MPI-Linux-64bit/bin ./paraview
Appendix B: Editing the PhysiCellReader_cells Python Script
In case you encounter an error reading your .mat file(s) containing cell data, you will probably need to manually edit the directory path to the file. This is illustrated below in a 4-step process: 1) select the Pipeline Browser tab, 2) select the PhysiCellReader_cells object, 3) select its Properties, then 4) edit the relevant information in the (Python) script. (The script frame is scrollable).
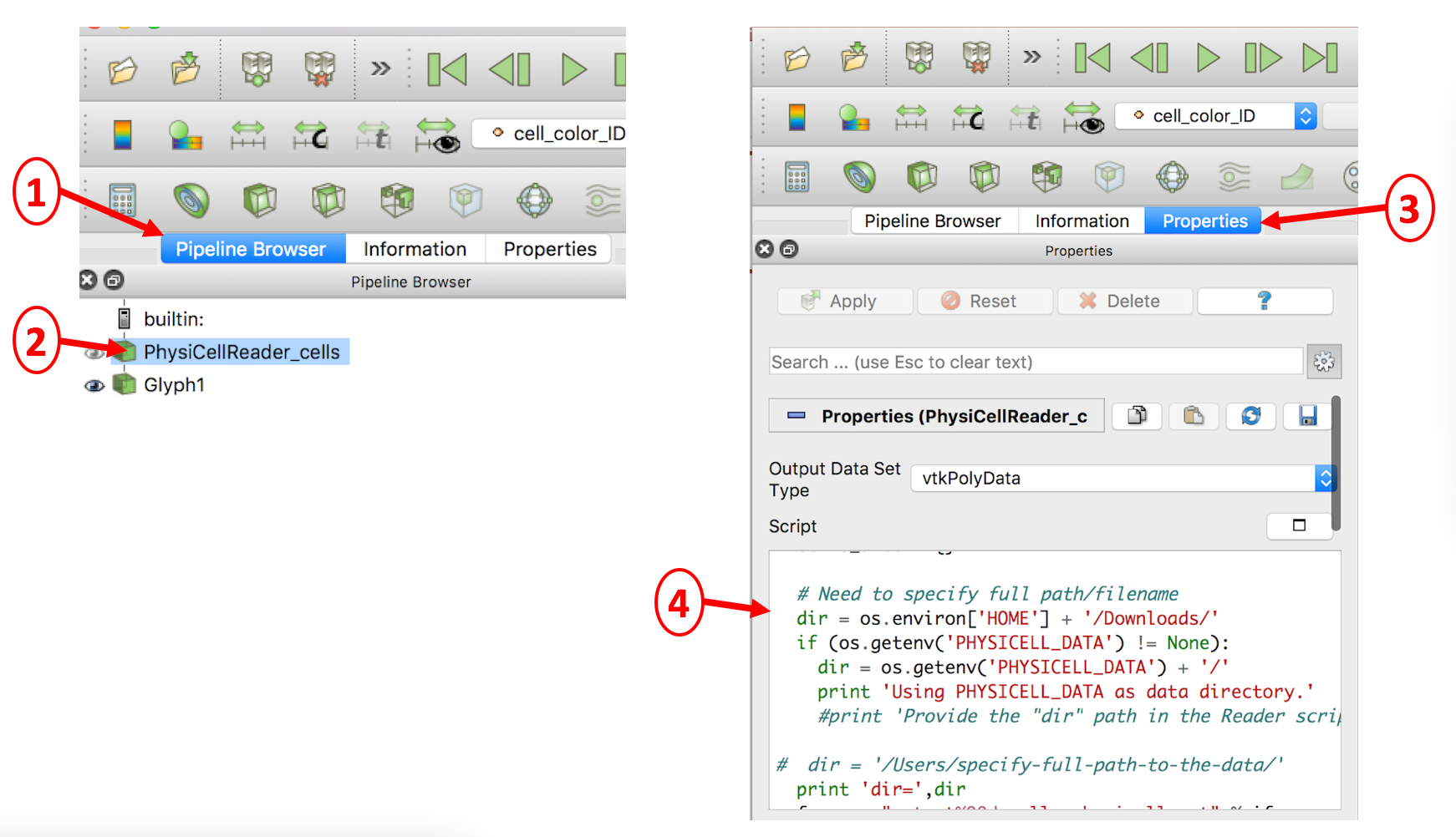
Adding a directory to your Windows path
When you’re setting your BioFVM / PhysiCell g++ development environment, you’ll need to add the compiler, MSYS, and your text editor (like Notepad++) to your system path. For example, you may need to add folders like these to your system PATH variable:
- c:\Program Files\mingw-w64\x86_64-5.3.0-win32-seh-rt_v4_rev0\mingw64\bin\
- c:\Program Files (x86)\Notepad++\
- C:\MinGW\msys\1.0\bin\
Here’s how to do that in various versions of Windows.
Windows XP, 7, and 8
First, open up a text editor, and concatenate your three paths into a single block of text, separated by semicolons (;):
- Open notepad ([Windows]+R, notepad)
- Type a semicolon, paste in the first path, and append a semicolon. It should look like this:
;c:\Program Files\mingw-w64\x86_64-5.3.0-win32-seh-rt_v4_rev0\mingw64\bin\;
- Paste in the next path, and append a semicolon. It should look like this:
;c:\Program Files\mingw-w64\x86_64-5.3.0-win32-seh-rt_v4_rev0\mingw64\bin\;C:\Program Files (x86)\Notepad++\;
- Paste in the last path, and append a semicolon. It should look something like this:
;c:\Program Files\mingw-w64\x86_64-5.3.0-win32-seh-rt_v4_rev0\mingw64\bin\;C:\Program Files (x86)\Notepad++\;c:\MinGW\msys\1.0\bin\;
Lastly, add these paths to the system path:
- Go the Start Menu, the right-click “This PC” or “My Computer”, and choose “Properties.”
- Click on “Advanced system settings”
- Click on “Environment Variables…” in the “Advanced” tab
- Scroll through the “System Variables” below until you find Path.
- Select “Path”, then click “Edit…”
- At the very end of “Variable Value”, paste what you made in Notepad in the prior steps. Make sure to paste at the end of the existing value, rather than overwriting it!
- Hit OK, OK, and OK to completely exit the “Advanced system settings.”
Windows 10:
Windows 10 has made it harder to find these settings, but easier to edit them. First, let’s find the system path:
- At the “run / search / Cortana” box next to the start menu, type “view advanced”, and you should see “view advanced system settings” auto-complete:
- Click to enter the advanced system settings, then choose environment variables … at the bottom of this box, and scroll down the list of user variables to Path
- Click on edit, then click New to add a new path. In the new entry (a new line), paste in your first new path (the compiler):
- Repeat this for the other two paths, then click OK, OK, Apply, OK to apply the new paths and exit.
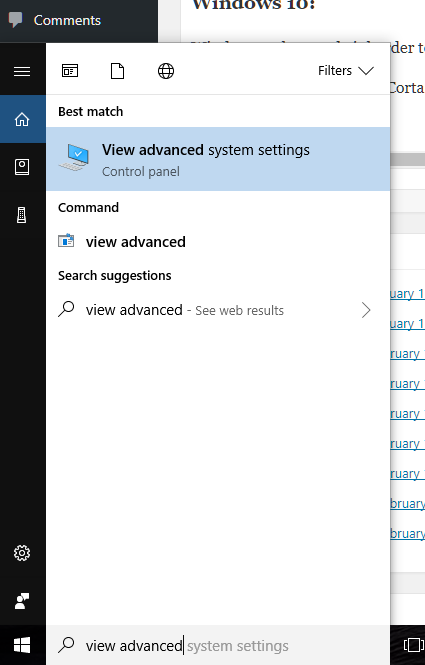
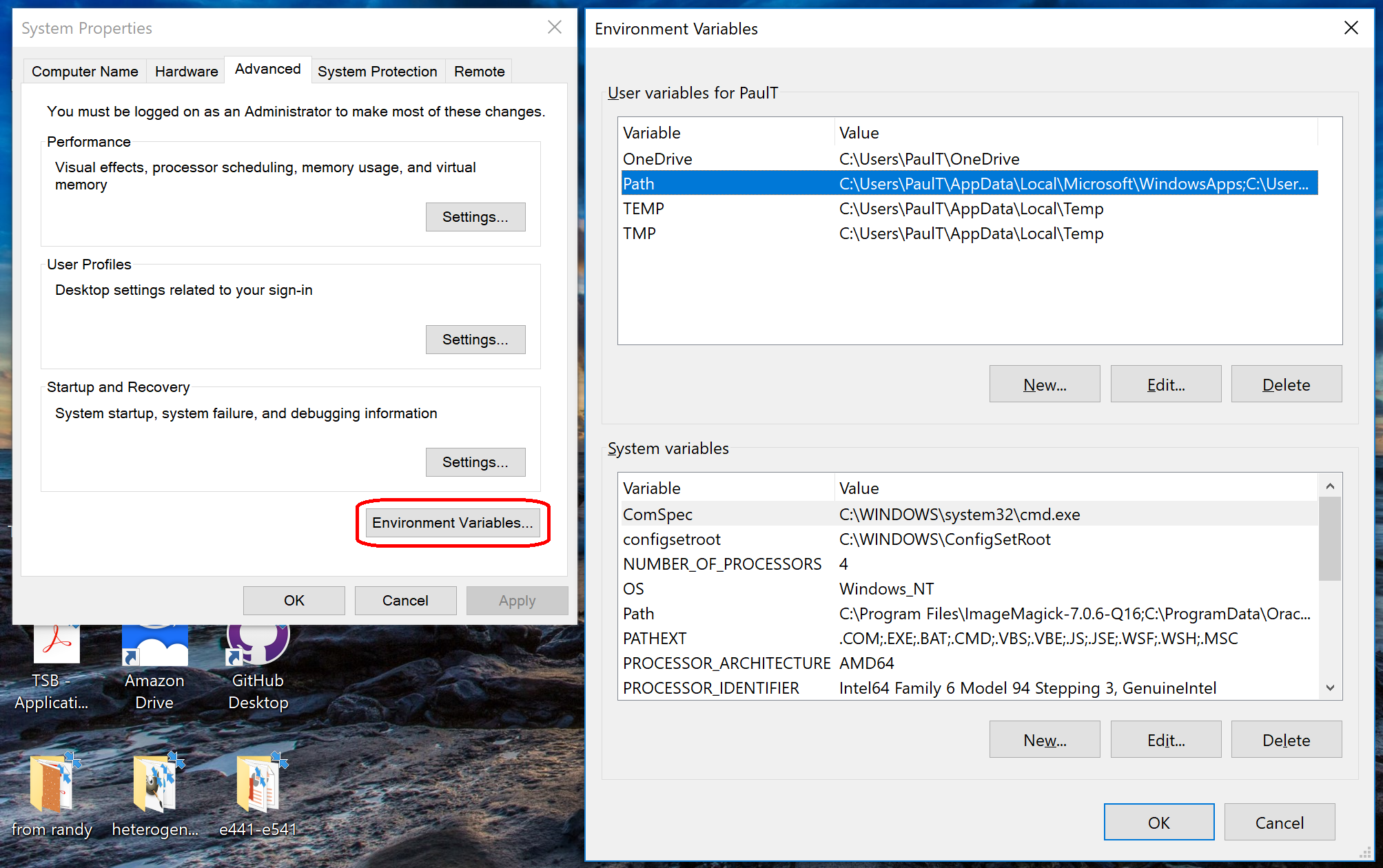
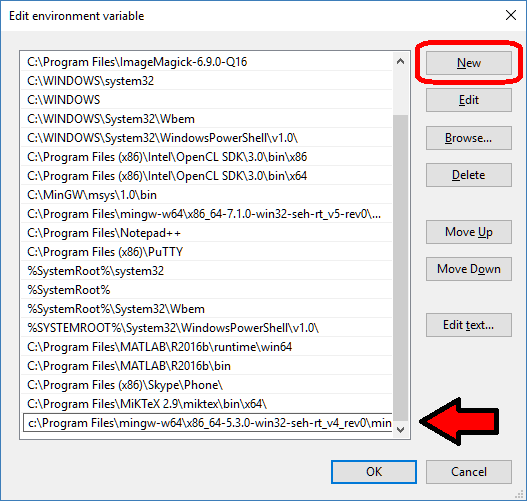
2018 Macklin lab speaking schedule
Members of Paul Macklin’s lab are speaking at the following events:
- February 3, 2018: Paul Macklin, at the 2018 Walther Cancer Foundation Symposium, hosted at Notre Dame
- Progress Towards High-Throughput Hypothesis Testing with Computational Modeling
- March 28, 2018, 2:00 pm: Paul Macklin, at the IUNI Open Science Form
- Title TBD
- Details here
- April 2, 2018: Paul Macklin, at the Visual Insights talk Series, Indiana University VIS lab
- Title TBD
- June 27-July 6, 2018: Paul Macklin, at the Virtual Tissues: Progress and Challenges in MultiCellular Systems Biology meeting, hosted by MATRIX Institute, University of Melbourne
- Title TBD
- July 8-12, 2018: Paul Macklin, Society for Mathematical Biology 2018 Annual Meeting, hosted by UNSW Sydney
- Title TBD
- Proposed minisymposium
- August 6-9, 2018: Paul Macklin, SIAM Life Sciences Meeting, hosted by University of Minnesota
- Title TBD
- Proposed minisymposium
Working with PhysiCell MultiCellDS digital snapshots in Matlab
PhysiCell 1.2.1 and later saves data as a specialized MultiCellDS digital snapshot, which includes chemical substrate fields, mesh information, and a readout of the cells and their phenotypes at single simulation time point. This tutorial will help you learn to use the matlab processing files included with PhysiCell.
This tutorial assumes you know (1) how to work at the shell / command line of your operating system, and (2) basic plotting and other functions in Matlab.
Key elements of a PhysiCell digital snapshot
A PhysiCell digital snapshot (a customized form of the MultiCellDS digital simulation snapshot) includes the following elements saved as XML and MAT files:
- output12345678.xml : This is the “base” output file, in MultiCellDS format. It includes key metadata such as when the file was created, the software, microenvironment information, and custom data saved at the simulation time. The Matlab files read this base file to find other related files (listed next). Example: output00003696.xml
- initial_mesh0.mat : This is the computational mesh information for BioFVM at time 0.0. Because BioFVM and PhysiCell do not use moving meshes, we do not save this data at any subsequent time.
- output12345678_microenvironment0.mat : This saves each biochemical substrate in the microenvironment at the computational voxels defined in the mesh (see above). Example: output00003696_microenvironment0.mat
- output12345678_cells.mat : This saves very basic cellular information related to BioFVM, including cell positions, volumes, secretion rates, uptake rates, and secretion saturation densities. Example: output00003696_cells.mat
- output12345678_cells_physicell.mat : This saves extra PhysiCell data for each cell agent, including volume information, cell cycle status, motility information, cell death information, basic mechanics, and any user-defined custom data. Example: output00003696_cells_physicell.mat
These snapshots make extensive use of Matlab Level 4 .mat files, for fast, compact, and well-supported saving of array data. Note that even if you cannot ready MultiCellDS XML files, you can work to parse the .mat files themselves.
The PhysiCell Matlab .m files
Every PhysiCell distribution includes some matlab functions to work with PhysiCell digital simulation snapshots, stored in the matlab subdirectory. The main ones are:
- composite_cutaway_plot.m : provides a quick, coarse 3-D cutaway plot of the discrete cells, with different colors for live (red), apoptotic (b), and necrotic (black) cells.
- read_MultiCellDS_xml.m : reads the “base” PhysiCell snapshot and its associated matlab files.
- set_MCDS_constants.m : creates a data structure MCDS_constants that has the same constants as PhysiCell_constants.h. This is useful for identifying cell cycle phases, etc.
- simple_cutaway_plot.m : provides a quick, coarse 3-D cutaway plot of user-specified cells.
- simple_plot.m : provides, a quick, coarse 3-D plot of the user-specified cells, without a cutaway or cross-sectional clipping plane.
A note on GNU Octave
Unfortunately, GNU octave does not include XML file parsing without some significant user tinkering. And one you’re done, it is approximately one order of magnitude slower than Matlab. Octave users can directly import the .mat files described above, but without the helpful metadata in the XML file. We’ll provide more information on the structure of these MAT files in a future blog post. Moreover, we plan to provide python and other tools for users without access to Matlab.
A sample digital snapshot
We provide a 3-D simulation snapshot from the final simulation time of the cancer-immune example in Ghaffarizadeh et al. (2017, in review) at:
The corresponding SVG cross-section for that time (through z = 0 μm) looks like this:

Unzip the sample dataset in any directory, and make sure the matlab files above are in the same directory (or in your Matlab path). If you’re inside matlab:
!unzip 3D_PhysiCell_matlab_sample.zip
Loading a PhysiCell MultiCellDS digital snapshot
Now, load the snapshot:
MCDS = read_MultiCellDS_xml( 'output00003696.xml');
This will load the mesh, substrates, and discrete cells into the MCDS data structure, and give a basic summary:
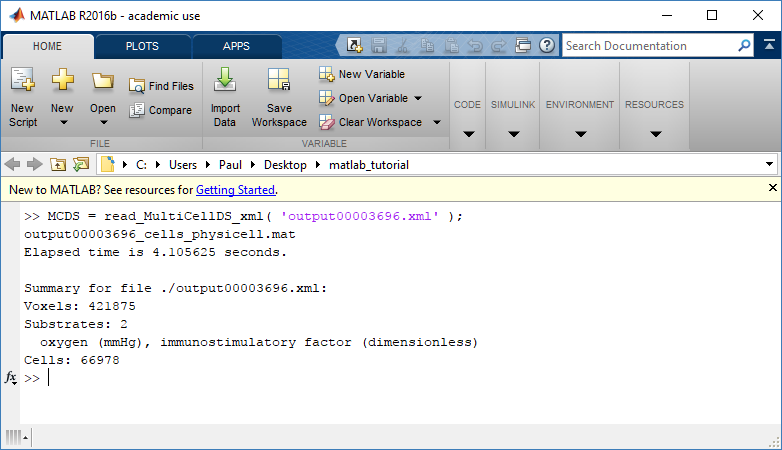
Typing ‘MCDS’ and then hitting ‘tab’ (for auto-completion) shows the overall structure of MCDS, stored as metadata, mesh, continuum variables, and discrete cells:
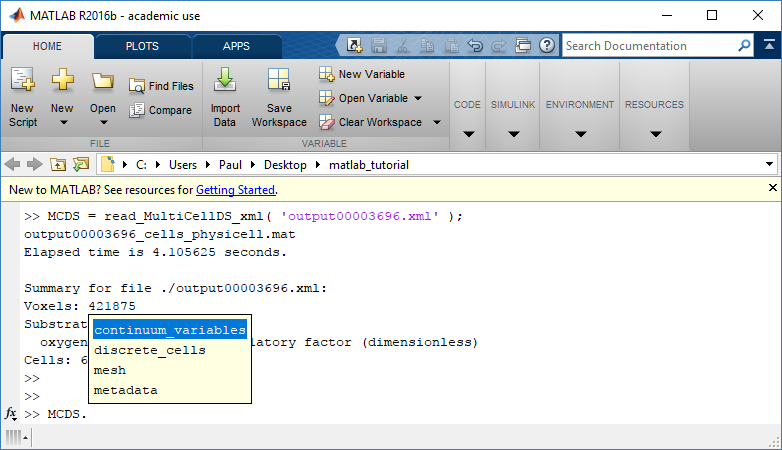
To get simulation metadata, such as the current simulation time, look at MCDS.metadata.current_time
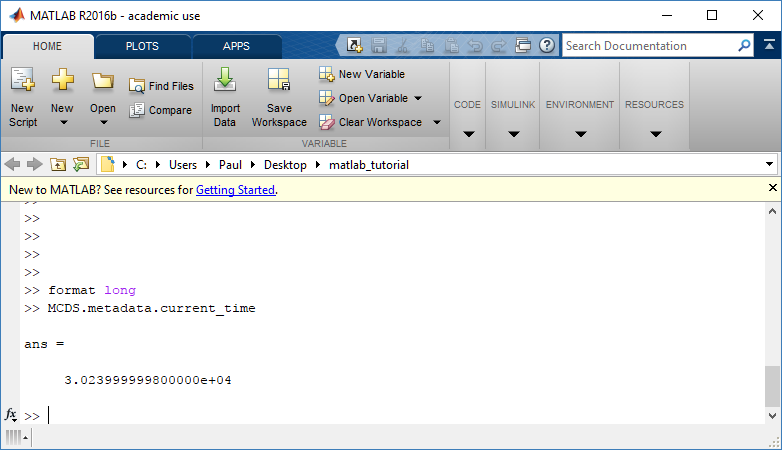
Here, we see that the current simulation time is 30240 minutes, or 21 days. MCDS.metadata.current_runtime gives the elapsed walltime to up to this point: about 53 hours (1.9e5 seconds), including file I/O time to write full simulation data once per 3 simulated minutes after the start of the adaptive immune response.
Plotting chemical substrates
Let’s make an oxygen contour plot through z = 0 μm. First, we find the index corresponding to this z-value:
k = find( MCDS.mesh.Z_coordinates == 0 );
Next, let’s figure out which variable is oxygen. Type “MCDS.continuum_variables.name”, which will show the array of variable names:
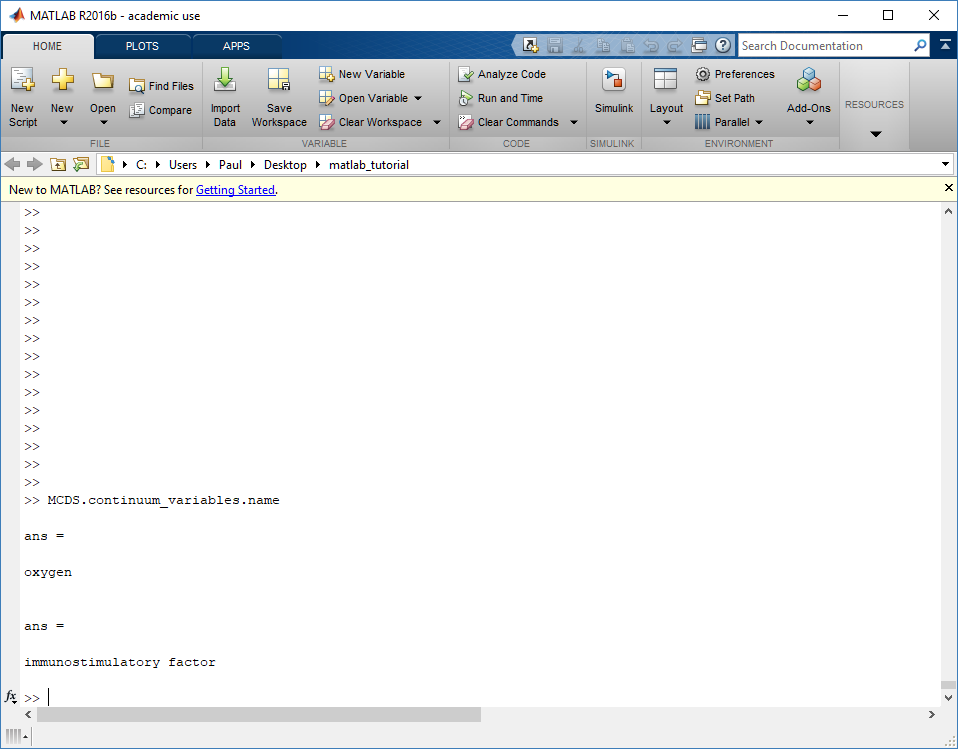
Here, oxygen is the first variable, (index 1). So, to make a filled contour plot:
contourf( MCDS.mesh.X(:,:,k), MCDS.mesh.Y(:,:,k), ...
MCDS.continuum_variables(1).data(:,:,k) , 20 ) ;
Now, let’s set this to a correct aspect ratio (no stretching in x or y), add a colorbar, and set the axis labels, using
metadata to get labels:
axis image colorbar xlabel( sprintf( 'x (%s)' , MCDS.metadata.spatial_units) ); ylabel( sprintf( 'y (%s)' , MCDS.metadata.spatial_units) );
Lastly, let’s add an appropriate (time-based) title:
title( sprintf('%s (%s) at t = %3.2f %s, z = %3.2f %s', MCDS.continuum_variables(1).name , ...
MCDS.continuum_variables(1).units , ...
MCDS.metadata.current_time , ...
MCDS.metadata.time_units, ...
MCDS.mesh.Z_coordinates(k), ...
MCDS.metadata.spatial_units ) );
Here’s the end result:
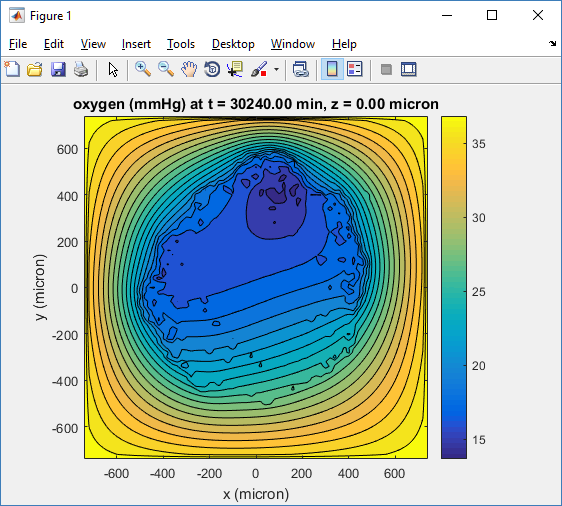
We can easily export graphics, such as to PNG format:
print( '-dpng' , 'output_o2.png' );
For more on plotting BioFVM data, see the tutorial
at http://www.mathcancer.org/blog/saving-multicellds-data-from-biofvm/
Plotting cells in space
3-D point cloud
First, let’s plot all the cells in 3D:
plot3( MCDS.discrete_cells.state.position(:,1) , MCDS.discrete_cells.state.position(:,2), ... MCDS.discrete_cells.state.position(:,3) , 'bo' );
At first glance, this does not look good: some cells are far out of the simulation domain, distorting the automatic range of the plot:
This does not ordinarily happen in PhysiCell (the default cell mechanics functions have checks to prevent such behavior), but this example includes a simple Hookean elastic adhesion model for immune cell attachment to tumor cells. In rare circumstances, an attached tumor cell or immune cell can apoptose on its own (due to its background apoptosis rate),
without “knowing” to detach itself from the surviving cell in the pair. The remaining cell attempts to calculate its elastic velocity based upon an invalid cell position (no longer in memory), creating an artificially large velocity that “flings” it out of the simulation domain. Such cells are not simulated any further, so this is effectively equivalent to an extra apoptosis event (only 3 cells are out of the simulation domain after tens of millions of cell-cell elastic adhesion calculations). Future versions of this example will include extra checks to prevent this rare behavior.
The plot can simply be fixed by changing the axis:
axis( 1000*[-1 1 -1 1 -1 1] ) axis square
Notice that this is a very difficult plot to read, and very non-interactive (laggy) to rotation and scaling operations. We can make a slightly nicer plot by searching for different cell types and plotting them with different colors:
% make it easier to work with the cell positions;
P = MCDS.discrete_cells.state.position;
% find type 1 cells
ind1 = find( MCDS.discrete_cells.metadata.type == 1 );
% better still, eliminate those out of the simulation domain
ind1 = find( MCDS.discrete_cells.metadata.type == 1 & ...
abs(P(:,1))' < 1000 & abs(P(:,2))' < 1000 & abs(P(:,3))' < 1000 );
% find type 0 cells
ind0 = find( MCDS.discrete_cells.metadata.type == 0 & ...
abs(P(:,1))' < 1000 & abs(P(:,2))' < 1000 & abs(P(:,3))' < 1000 );
%now plot them
P = MCDS.discrete_cells.state.position;
plot3( P(ind0,1), P(ind0,2), P(ind0,3), 'bo' )
hold on
plot3( P(ind1,1), P(ind1,2), P(ind1,3), 'ro' )
hold off
axis( 1000*[-1 1 -1 1 -1 1] )
axis square
However, this isn’t much better. You can use the scatter3 function to gain more control on the size and color of the plotted cells, or even make macros to plot spheres in the cell locations (with shading and lighting), but Matlab is very slow when plotting beyond 103 cells. Instead, we recommend the faster preview functions below for data exploration, and higher-quality plotting (e.g., by POV-ray) for final publication-
Fast 3-D cell data previewers
Notice that plot3 and scatter3 are painfully slow for any nontrivial number of cells. We can use a few fast previewers to quickly get a sense of the data. First, let’s plot all the dead cells, and make them red:
clf simple_plot( MCDS, MCDS, MCDS.discrete_cells.dead_cells , 'r' )
This function creates a coarse-grained 3-D indicator function (0 if no cells are present; 1 if they are), and plots a 3-D level surface. It is very responsive to rotations and other operations to explore the data. You may notice the second argument is a list of indices: only these cells are plotted. This gives you a method to select cells with specific characteristics when plotting. (More on that below.) If you want to get a sense of the interior structure, use a cutaway plot:
clf simple_cutaway_plot( MCDS, MCDS, MCDS.discrete_cells.dead_cells , 'r' )
We also provide a fast “composite” cutaway which plots all live cells as red, apoptotic cells as blue (without the cutaway), and all necrotic cells as black:
clf composite_cutaway_plot( MCDS )

Lastly, we show an improved plot that uses different colors for the immune cells, and Matlab’s “find” function to help set up the indexing:
constants = set_MCDS_constants
% find the type 0 necrotic cells
ind0_necrotic = find( MCDS.discrete_cells.metadata.type == 0 & ...
(MCDS.discrete_cells.phenotype.cycle.current_phase == constants.necrotic_swelling | ...
MCDS.discrete_cells.phenotype.cycle.current_phase == constants.necrotic_lysed | ...
MCDS.discrete_cells.phenotype.cycle.current_phase == constants.necrotic) );
% find the live type 0 cells
ind0_live = find( MCDS.discrete_cells.metadata.type == 0 & ...
(MCDS.discrete_cells.phenotype.cycle.current_phase ~= constants.necrotic_swelling & ...
MCDS.discrete_cells.phenotype.cycle.current_phase ~= constants.necrotic_lysed & ...
MCDS.discrete_cells.phenotype.cycle.current_phase ~= constants.necrotic & ...
MCDS.discrete_cells.phenotype.cycle.current_phase ~= constants.apoptotic) );
clf
% plot live tumor cells red, in cutaway view
simple_cutaway_plot( MCDS, ind0_live , 'r' );
hold on
% plot dead tumor cells black, in cutaway view
simple_cutaway_plot( MCDS, ind0_necrotic , 'k' )
% plot all immune cells, but without cutaway (to show how they infiltrate)
simple_plot( MCDS, ind1, 'g' )
hold off
A small cautionary note on future compatibility
PhysiCell 1.2.1 uses the <custom> data tag (allowed as part of the MultiCellDS specification) to encode its cell data, to allow a more compact data representation, because the current PhysiCell daft does not support such a formulation, and Matlab is painfully slow at parsing XML files larger than ~50 MB. Thus, PhysiCell snapshots are not yet fully compatible with general MultiCellDS tools, which would by default ignore custom data. In the future, we will make available converter utilities to transform “native” custom PhysiCell snapshots to MultiCellDS snapshots that encode all the cellular information in a more verbose but compatible XML format.
Closing words and future work
Because Octave is not a great option for parsing XML files (with critical MultiCellDS metadata), we plan to write similar functions to read and plot PhysiCell snapshots in Python, as an open source alternative. Moreover, our lab in the next year will focus on creating further MultiCellDS configuration, analysis, and visualization routines. We also plan to provide additional 3-D functions for plotting the discrete cells and varying color with their properties.
In the longer term, we will develop open source, stand-alone analysis and visualization tools for MultiCellDS snapshots (including PhysiCell snapshots). Please stay tuned!
Frequently Asked Questions (FAQs) for Building PhysiCell
Here, we document common problems and solutions in compiling and running PhysiCell projects.
Compiling Errors
I get the error “clang: error: unsupported option ‘-fopenmp’” when I compile a PhysiCell Project
When compiling a PhysiCell project in OSX, you may see an error like this:

This shows that clang is being used as the compiler, instead of g++. If you are using PhysiCell 1.2.2 or later, fix this error by setting the PHYSICELL_CPP environment variable. If you installed by Homebrew:
echo export PATH=/usr/local/bin:$PATH >> ~/.bash_profile
If you installed by MacPorts:
echo export PHYSICELL_CPP=g++-mp-7 >> ~/.bash_profile
To fix this error in earlier versions of PhysiCell (1.2.1 or earlier), edit your Makefile, and fix the CC line.
CC := g++-7 # use this if you installed g++ 7 by Homebrew
or
CC := g++-mp-7 # use this if you installed g++ 7 by MacPorts
If you have not installed g++ by MacPorts or Homebrew, please see the following tutorials:
When I compile, I get tons of weird “no such instruction” errors like
“no such instruction: `vmovsd (%rdx,%rax), #xmm0′” or
“no such instruction: `vfnmadd132sd (%rsi,%rax,8), $xmm5,%xmm0′”
When you compile, you may see a huge list of arcane symbols, like this:
 The “no such instruction” means that the compiler is trying to send CPU instructions (like these vmovsd lines) that your system doesn’t understand. (It’s like trying SSE4 instructions on a Pentium 4.) The first solution to try is to use a safer architecture, using the ARCH definition. Open your Makefile, and search for the ARCH line. If it isn’t set to native, then try that. If it is already set to native, try a safer, older architecture like core2 by commenting out native (add a # symbol to any Makefile line to comment it out), and uncommenting the core2 line:
The “no such instruction” means that the compiler is trying to send CPU instructions (like these vmovsd lines) that your system doesn’t understand. (It’s like trying SSE4 instructions on a Pentium 4.) The first solution to try is to use a safer architecture, using the ARCH definition. Open your Makefile, and search for the ARCH line. If it isn’t set to native, then try that. If it is already set to native, try a safer, older architecture like core2 by commenting out native (add a # symbol to any Makefile line to comment it out), and uncommenting the core2 line:
# ARCH := native ARCH := core2
“I don’t understand the ‘m’ flag!”
When you compile a project, you may see an error that looks like this:
This seems to be due to incompatibilities between MacPort’s gcc chain and Homebrew (especially if you installed gcc5 in MacPorts). As we showed in this tutorial, you can open a terminal window and run a single command to fix it:
echo export PATH=/usr/bin:$PATH >> ~/.profile
Note that you’ll need to restart your terminal to fully apply the fix.
Errors Running PhysiCell
My project compiles fine, but when I run it, I get errors like “illegal instruction: 4“.
This means that PhysiCell has been compiled for the wrong architecture, and it is sending unsupported instructions to your CPU. See the “no such instruction” error above for a fix.
I fixed my Makefile, and things compiled fine, but I can’t compile a different project or the sample projects.
For PhysiCell 1.2.2 or later:
The Makefile rules for the sample projects (e.g., make biorobots-sample) overwrite the Makefile in the PhysiCell root directory, so you’ll need to return to the original state to re-populate with a new
sample project. Use
make reset
and then you’ll be good to go. As promised (below), we updated PhysiCell so that OSX users don’t need to fix the CC line for every single Makefile.
For PhysiCell 1.2.1 and earlier:
The Makefile rules for the sample projects (e.g., make biorobots-sample) overwrite the Makefile in the PhysiCell root directory, so you’ll need to re-modify the Makefile with the correct CC (and potentially ARCH) lines any time you run a template project or sample project make rule. This will be improved in future editions of PhysiCell. Sorry!!
It compiled fine, but the project crashes with “Segmentation fault: 11″, or the program just crashes with “killed.”
Everything compiles just fine and your program starts, but you may get a segmentation fault either early on, or later in your simulation. Like this:
[Screenshot soon! This error is rare.]
Or on Linux systems it might just crash with a simple “killed” message:
This error occurs if there is not enough (contiguous) memory to run a project. If you are running in a Virtual Machine, you can solve this by increasing the amount of memory. If you are running “natively” you may need to install more RAM or decrease the problem size (the size of the simulation domain or the number of cells). To date, we have only encountered this error on virtual machines with little memory. We recommend using 8192 MB (8 GB):