Category: math
A small computational thought experiment
In Macklin (2017), I briefly touched on a simple computational thought experiment that shows that for a group of homogeneous cells, you can observe substantial heterogeneity in cell behavior. This “thought experiment” is part of a broader preview and discussion of a fantastic paper by Linus Schumacher, Ruth Baker, and Philip Maini published in Cell Systems, where they showed that a migrating collective homogeneous cells can show heterogeneous behavior when quantitated with new migration metrics. I highly encourage you to check out their work!
In this blog post, we work through my simple thought experiment in a little more detail.
Note: If you want to reference this blog post, please cite the Cell Systems preview article:
P. Macklin, When seeing isn’t believing: How math can guide our interpretation of measurements and experiments. Cell Sys., 2017 (in press). DOI: 10.1016/j.cells.2017.08.005
The thought experiment
Consider a simple (and widespread) model of a population of cycling cells: each virtual cell (with index i) has a single “oncogene” \( r_i \) that sets the rate of progression through the cycle. Between now (t) and a small time from now ( \(t+\Delta t\)), the virtual cell has a probability \(r_i \Delta t\) of dividing into two daughter cells. At the population scale, the overall population growth model that emerges from this simple single-cell model is:
\[\frac{dN}{dt} = \langle r\rangle N, \]
where \( \langle r \rangle \) the mean division rate over the cell population, and N is the number of cells. See the discussion in the supplementary information for Macklin et al. (2012).
Now, suppose (as our thought experiment) that we could track individual cells in the population and track how long it takes them to divide. (We’ll call this the division time.) What would the distribution of cell division times look like, and how would it vary with the distribution of the single-cell rates \(r_i\)?
Mathematical method
In the Matlab script below, we implement this cell cycle model as just about every discrete model does. Here’s the pseudocode:
t = 0;
while( t < t_max )
for i=1:Cells.size()
u = random_number();
if( u < Cells[i].birth_rate * dt )
Cells[i].division_time = Cells[i].age;
Cells[i].divide();
end
end
t = t+dt;
end
That is, until we’ve reached the final simulation time, loop through all the cells and decide if they should divide: For each cell, choose a random number between 0 and 1, and if it’s smaller than the cell’s division probability (\(r_i \Delta t\)), then divide the cell and write down the division time.
As an important note, we have to track the same cells until they all divide, rather than merely record which cells have divided up to the end of the simulation. Otherwise, we end up with an observational bias that throws off our recording. See more below.
The sample code
You can download the Matlab code for this example at:
http://MathCancer.org/files/matlab/thought_experiment_matlab(Macklin_Cell_Systems_2017).zip
Extract all the files, and run “thought_experiment” in Matlab (or Octave, if you don’t have a Matlab license or prefer an open source platform) for the main result.
All these Matlab files are available as open source, under the GPL license (version 3 or later).
Results and discussion
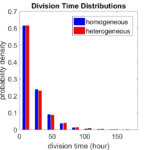
First, let’s see what happens if all the cells are identical, with \(r = 0.05 \textrm{ hr}^{-1}\). We run the script, and track the time for each of 10,000 cells to divide. As expected by theory (Macklin et al., 2012) (but perhaps still a surprise if you haven’t looked), we get an exponential distribution of division times, with mean time \(1/\langle r \rangle\):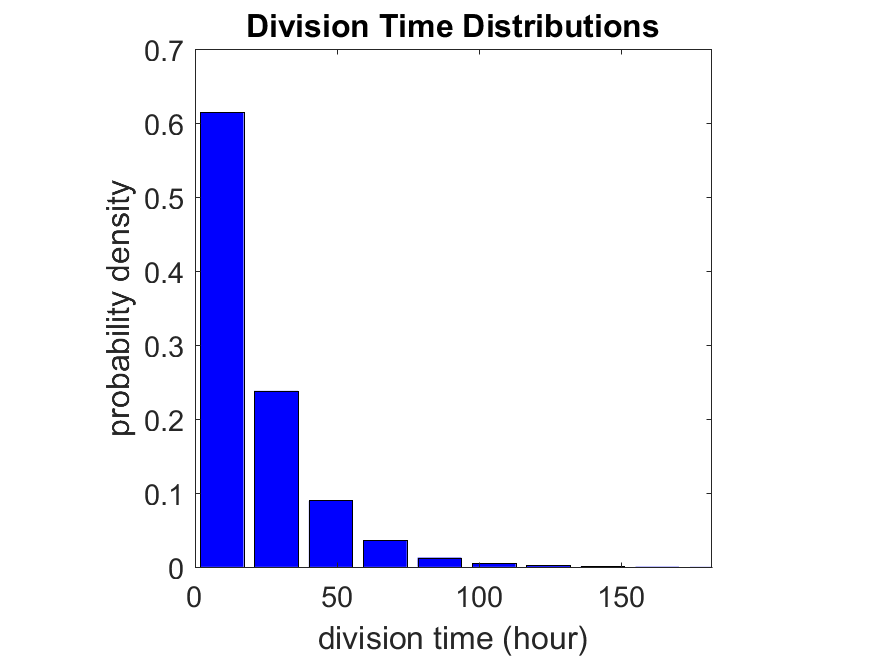
So even in this simple model, a homogeneous population of cells can show heterogeneity in their behavior. Here’s the interesting thing: let’s now give each cell its own division parameter \(r_i\) from a normal distribution with mean \(0.05 \textrm{ hr}^{-1}\) and a relative standard deviation of 25%: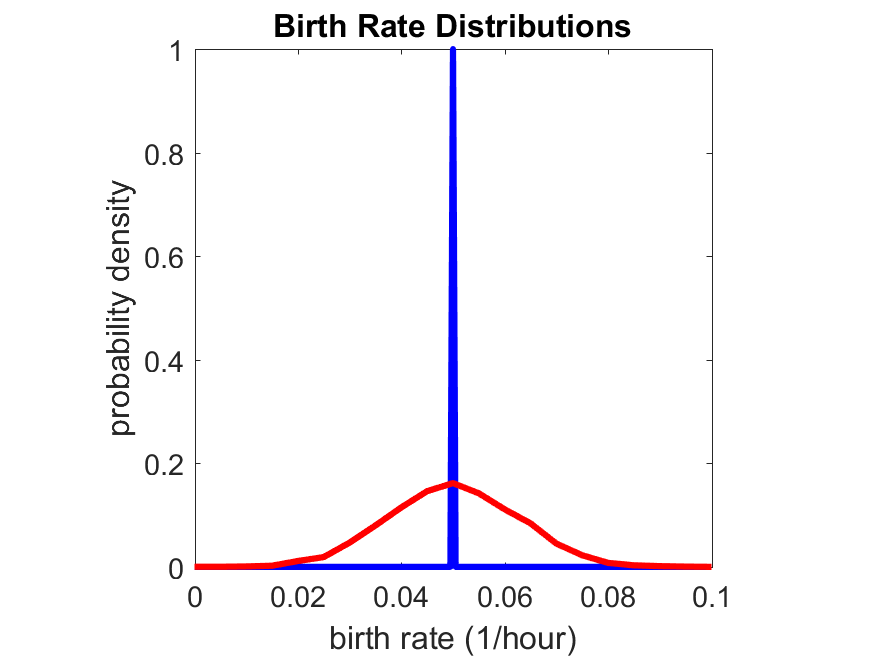
If we repeat the experiment, we get the same distribution of cell division times!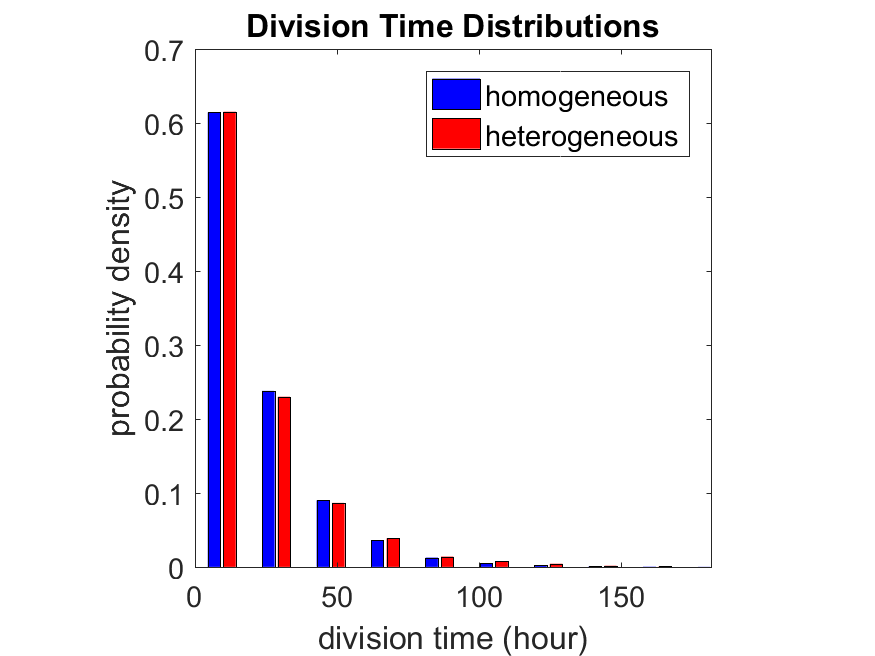
So in this case, based solely on observations of the phenotypic heterogeneity (the division times), it is impossible to distinguish a “genetically” homogeneous cell population (one with identical parameters) from a truly heterogeneous population. We would require other metrics, like tracking changes in the mean division time as cells with a higher \(r_i\) out-compete the cells with lower \(r_i\).
Lastly, I want to point out that caution is required when designing these metrics and single-cell tracking. If instead we had tracked all cells throughout the simulated experiment, including new daughter cells, and then recorded the first 10,000 cell division events, we would get a very different distribution of cell division times: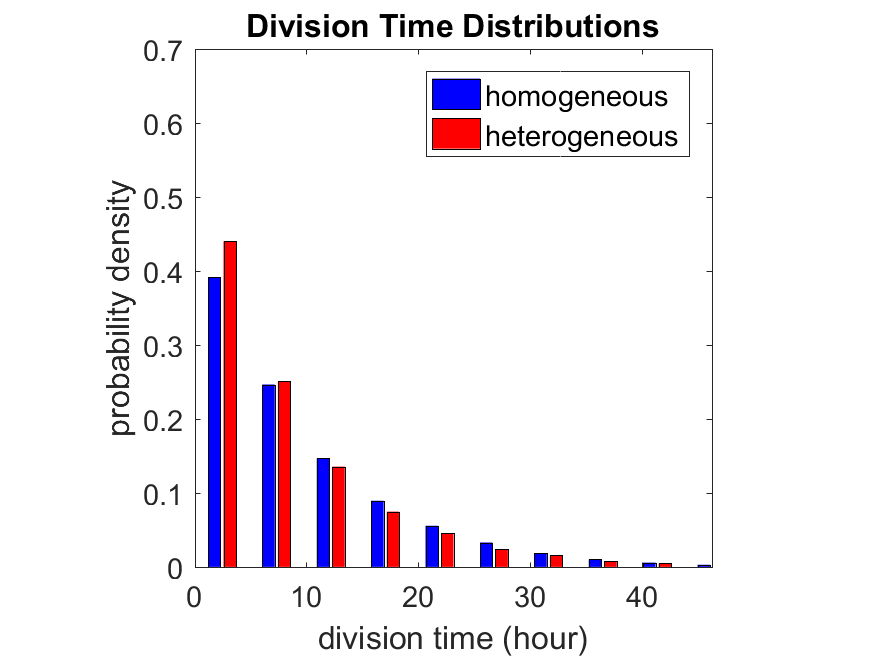
By only recording the division times for the cells that have divided, and not those that haven’t, we bias our observations towards cells with shorter division times. Indeed, the mean division time for this simulated experiment is far lower than we would expect by theory. You can try this one by running “bad_thought_experiment”.
Further reading
This post is an expansion of our recent preview in Cell Systems in Macklin (2017):
P. Macklin, When seeing isn’t believing: How math can guide our interpretation of measurements and experiments. Cell Sys., 2017 (in press). DOI: 10.1016/j.cells.2017.08.005
And the original work on apparent heterogeneity in collective cell migration is by Schumacher et al. (2017):
L. Schumacher et al., Semblance of Heterogeneity in Collective Cell Migration. Cell Sys., 2017 (in press). DOI: 10.1016/j.cels.2017.06.006
You can read some more on relating exponential distributions and Poisson processes to common discrete mathematical models of cell populations in Macklin et al. (2012):
P. Macklin, et al., Patient-calibrated agent-based modelling of ductal carcinoma in situ (DCIS): From microscopic measurements to macroscopic predictions of clinical progression. J. Theor. Biol. 301:122-40, 2012. DOI: 10.1016/j.jtbi.2012.02.002.
Lastly, I’d be delighted if you took a look at the open source software we have been developing for 3-D simulations of multicellular systems biology:
http://OpenSource.MathCancer.org
And you can always keep up-to-date by following us on Twitter: @MathCancer.
Coarse-graining discrete cell cycle models

Introduction
One observation that often goes underappreciated in computational biology discussions is that a computational model is often a model of a model of a model of biology: that is, it’s a numerical approximation (a model) of a mathematical model of an experimental model of a real-life biological system. Thus, there are three big places where a computational investigation can fall flat:
- The experimental model may be a bad choice for the disease or process (not our fault).
- Second, the mathematical model of the experimental system may have flawed assumptions (something we have to evaluate).
- The numerical implementation may have bugs or otherwise be mathematically inconsistent with the mathematical model.
Critically, you can’t use simulations to evaluate the experimental model or the mathematical model until you verify that the numerical implementation is consistent with the mathematical model, and that the numerical solution converges as \( \Delta t\) and \( \Delta x \) shrink to zero.
There are numerous ways to accomplish this, but ideally, it boils down to having some analytical solutions to the mathematical model, and comparing numerical solutions to these analytical or theoretical results. In this post, we’re going to walk through the math of analyzing a typical type of discrete cell cycle model.
Discrete model
Suppose we have a cell cycle model consisting of phases \(P_1, P_2, \ldots P_n \), where cells in the \(P_i\) phase progress to the \(P_{i+1}\) phase after a mean waiting time of \(T_i\), and cells leaving the \(P_n\) phase divide into two cells in the \(P_1\) phase. Assign each cell agent \(k\) a current phenotypic phase \( S_k(t) \). Suppose also that each phase \( i \) has a death rate \( d_i \), and that cells persist for on average \( T_\mathrm{A} \) time in the dead state before they are removed from the simulation.
The mean waiting times \( T_i \) are equivalent to transition rates \( r_i = 1 / T_i \) (Macklin et al. 2012). Moreover, for any time interval \( [t,t+\Delta t] \), both are equivalent to a transition probability of
\[ \mathrm{Prob}\Bigl( S_k(t+\Delta t) = P_{i+1} | S(t) = P_i \Bigr) = 1 – e^{ -r_i \Delta t } \approx r_i \Delta t = \frac{ \Delta t}{ T_i}. \] In many discrete models (especially cellular automaton models) with fixed step sizes \( \Delta t \), models are stated in terms of transition probabilities \( p_{i,i+1} \), which we see are equivalent to the work above with \( p_{i,i+1} = r_i \Delta t = \Delta t / T_i \), allowing us to tie mathematical model forms to biological, measurable parameters. We note that each \(T_i\) is the average duration of the \( P_i \) phase.
Concrete example: a Ki67 Model
Ki-67 is a nuclear protein that is expressed through much of the cell cycle, including S, G2, M, and part of G1 after division. It is used very commonly in pathology to assess proliferation, particularly in cancer. See the references and discussion in (Macklin et al. 2012). In Macklin et al. (2012), we came up with a discrete cell cycle model to match Ki-67 data (along with cleaved Caspase-3 stains for apoptotic cells). Let’s summarize the key parts here.
Each cell agent \(i\) has a phase \(S_i(t)\). Ki67- cells are quiescent (phase \(Q\), mean duration \( T_\mathrm{Q} \)), and they can enter the Ki67+ \(K_1\) phase (mean duration \(T_1\)). When \( K_1 \) cells leave their phase, they divide into two Ki67+ daughter cells in the \( K_2 \) phase with mean duration \( T_2 \). When cells exit \( K_2 \), they return to \( Q \). Cells in any phase can become apoptotic (enter the \( A \) phase with mean duration \( T_\mathrm{A} \)), with death rate \( r_\mathrm{A} \).
Coarse-graining to an ODE model
If each phase \(i\) has a death rate \(d_i\), if \( N_i(t) \) denotes the number of cells in the \( P_i \) phase at time \( t\), and if \( A(t) \) is the number of dead (apoptotic) cells at time \( t\), then on average, the number of cells in the \( P_i \) phase at the next time step is given by
\[ N_i(t+\Delta t) = N_i(t) + N_{i-1}(t) \cdot \left[ \textrm{prob. of } P_{i-1} \rightarrow P_i \textrm{ transition} \right] – N_i(t) \cdot \left[ \textrm{prob. of } P_{i} \rightarrow P_{i+1} \textrm{ transition} \right] \] \[ – N_i(t) \cdot \left[ \textrm{probability of death} \right] \] By the work above, this is:
\[ N_i(t+\Delta t) \approx N_i(t) + N_{i-1}(t) r_{i-1} \Delta t – N_i(t) r_i \Delta t – N_i(t) d_i \Delta t , \] or after shuffling terms and taking the limit as \( \Delta t \downarrow 0\), \[ \frac{d}{dt} N_i(t) = r_{i-1} N_{i-1}(t) – \left( r_i + d_i \right) N_i(t). \] Continuing this analysis, we obtain a linear system:
\[ \frac{d}{dt}{ \vec{N} } = \begin{bmatrix} -(r_1+d_1) & 0 & \cdots & 0 & 2r_n & 0 \\ r_1 & -(r_2+d_2) & 0 & \cdots & 0 & 0 \\ 0 & r_2 & -(r_3+d_3) & 0 & \cdots & 0 \\ & & \ddots & & \\0&\cdots&0 &r_{n-1} & -(r_n+d_n) & 0 \\ d_1 & d_2 & \cdots & d_{n-1} & d_n & -\frac{1}{T_\mathrm{A}} \end{bmatrix}\vec{N} = M \vec{N}, \] where \( \vec{N}(t) = [ N_1(t), N_2(t) , \ldots , N_n(t) , A(t) ] \).
For the Ki67 model above, let \(\vec{N} = [K_1, K_2, Q, A]\). Then the linear system is
\[ \frac{d}{dt} \vec{N} = \begin{bmatrix} -\left( \frac{1}{T_1} + r_\mathrm{A} \right) & 0 & \frac{1}{T_\mathrm{Q}} & 0 \\ \frac{2}{T_1} & -\left( \frac{1}{T_2} + r_\mathrm{A} \right) & 0 & 0 \\ 0 & \frac{1}{T_2} & -\left( \frac{1}{T_\mathrm{Q}} + r_\mathrm{A} \right) & 0 \\ r_\mathrm{A} & r_\mathrm{A} & r_\mathrm{A} & -\frac{1}{T_\mathrm{A}} \end{bmatrix} \vec{N} .\]
(If we had written \( \vec{N} = [Q, K_1, K_2 , A] \), then the matrix above would have matched the general form.)
Some theoretical results
If \( M\) has eigenvalues \( \lambda_1 , \ldots \lambda_{n+1} \) and corresponding eigenvectors \( \vec{v}_1, \ldots , \vec{v}_{n+1} \), then the general solution is given by
\[ \vec{N}(t) = \sum_{i=1}^{n+1} c_i e^{ \lambda_i t } \vec{v}_i ,\] and if the initial cell counts are given by \( \vec{N}(0) \) and we write \( \vec{c} = [c_1, \ldots c_{n+1} ] \), we can obtain the coefficients by solving \[ \vec{N}(0) = [ \vec{v}_1 | \cdots | \vec{v}_{n+1} ]\vec{c} .\] In many cases, it turns out that all but one of the eigenvalues (say \( \lambda \) with corresponding eigenvector \(\vec{v}\)) are negative. In this case, all the other components of the solution decay away, and for long times, we have \[ \vec{N}(t) \approx c e^{ \lambda t } \vec{v} .\] This is incredibly useful, because it says that over long times, the fraction of cells in the \( i^\textrm{th} \) phase is given by \[ v_{i} / \sum_{j=1}^{n+1} v_{j}. \]
Matlab implementation (with the Ki67 model)
First, let’s set some parameters, to make this a little easier and reusable.
parameters.dt = 0.1; % 6 min = 0.1 hours parameters.time_units = 'hour'; parameters.t_max = 3*24; % 3 days parameters.K1.duration = 13; parameters.K1.death_rate = 1.05e-3; parameters.K1.initial = 0; parameters.K2.duration = 2.5; parameters.K2.death_rate = 1.05e-3; parameters.K2.initial = 0; parameters.Q.duration = 74.35 ; parameters.Q.death_rate = 1.05e-3; parameters.Q.initial = 1000; parameters.A.duration = 8.6; parameters.A.initial = 0;
Next, we write a function to read in the parameter values, construct the matrix (and all the data structures), find eigenvalues and eigenvectors, and create the theoretical solution. It also finds the positive eigenvalue to determine the long-time values.
function solution = Ki67_exact( parameters )
% allocate memory for the main outputs
solution.T = 0:parameters.dt:parameters.t_max;
solution.K1 = zeros( 1 , length(solution.T));
solution.K2 = zeros( 1 , length(solution.T));
solution.K = zeros( 1 , length(solution.T));
solution.Q = zeros( 1 , length(solution.T));
solution.A = zeros( 1 , length(solution.T));
solution.Live = zeros( 1 , length(solution.T));
solution.Total = zeros( 1 , length(solution.T));
% allocate memory for cell fractions
solution.AI = zeros(1,length(solution.T));
solution.KI1 = zeros(1,length(solution.T));
solution.KI2 = zeros(1,length(solution.T));
solution.KI = zeros(1,length(solution.T));
% get the main parameters
T1 = parameters.K1.duration;
r1A = parameters.K1.death_rate;
T2 = parameters.K2.duration;
r2A = parameters.K2.death_rate;
TQ = parameters.Q.duration;
rQA = parameters.Q.death_rate;
TA = parameters.A.duration;
% write out the mathematical model:
% d[Populations]/dt = Operator*[Populations]
Operator = [ -(1/T1 +r1A) , 0 , 1/TQ , 0; ...
2/T1 , -(1/T2 + r2A) ,0 , 0; ...
0 , 1/T2 , -(1/TQ + rQA) , 0; ...
r1A , r2A, rQA , -1/TA ];
% eigenvectors and eigenvalues
[V,D] = eig(Operator);
eigenvalues = diag(D);
% save the eigenvectors and eigenvalues in case you want them.
solution.V = V;
solution.D = D;
solution.eigenvalues = eigenvalues;
% initial condition
VecNow = [ parameters.K1.initial ; parameters.K2.initial ; ...
parameters.Q.initial ; parameters.A.initial ] ;
solution.K1(1) = VecNow(1);
solution.K2(1) = VecNow(2);
solution.Q(1) = VecNow(3);
solution.A(1) = VecNow(4);
solution.K(1) = solution.K1(1) + solution.K2(1);
solution.Live(1) = sum( VecNow(1:3) );
solution.Total(1) = sum( VecNow(1:4) );
solution.AI(1) = solution.A(1) / solution.Total(1);
solution.KI1(1) = solution.K1(1) / solution.Total(1);
solution.KI2(1) = solution.K2(1) / solution.Total(1);
solution.KI(1) = solution.KI1(1) + solution.KI2(1);
% now, get the coefficients to write the analytic solution
% [Populations] = c1*V(:,1)*exp( d(1,1)*t) + c2*V(:,2)*exp( d(2,2)*t ) +
% c3*V(:,3)*exp( d(3,3)*t) + c4*V(:,4)*exp( d(4,4)*t );
coeff = linsolve( V , VecNow );
% find the (hopefully one) positive eigenvalue.
% eigensolutions with negative eigenvalues decay,
% leaving this as the long-time behavior.
eigenvalues = diag(D);
n = find( real( eigenvalues ) &gt; 0 )
solution.long_time.KI1 = V(1,n) / sum( V(:,n) );
solution.long_time.KI2 = V(2,n) / sum( V(:,n) );
solution.long_time.QI = V(3,n) / sum( V(:,n) );
solution.long_time.AI = V(4,n) / sum( V(:,n) ) ;
solution.long_time.KI = solution.long_time.KI1 + solution.long_time.KI2;
% now, write out the solution at all the times
for i=2:length( solution.T )
% compact way to write the solution
VecExact = real( V*( coeff .* exp( eigenvalues*solution.T(i) ) ) );
solution.K1(i) = VecExact(1);
solution.K2(i) = VecExact(2);
solution.Q(i) = VecExact(3);
solution.A(i) = VecExact(4);
solution.K(i) = solution.K1(i) + solution.K2(i);
solution.Live(i) = sum( VecExact(1:3) );
solution.Total(i) = sum( VecExact(1:4) );
solution.AI(i) = solution.A(i) / solution.Total(i);
solution.KI1(i) = solution.K1(i) / solution.Total(i);
solution.KI2(i) = solution.K2(i) / solution.Total(i);
solution.KI(i) = solution.KI1(i) + solution.KI2(i);
end
return;
Now, let’s run it and see what this thing looks like:
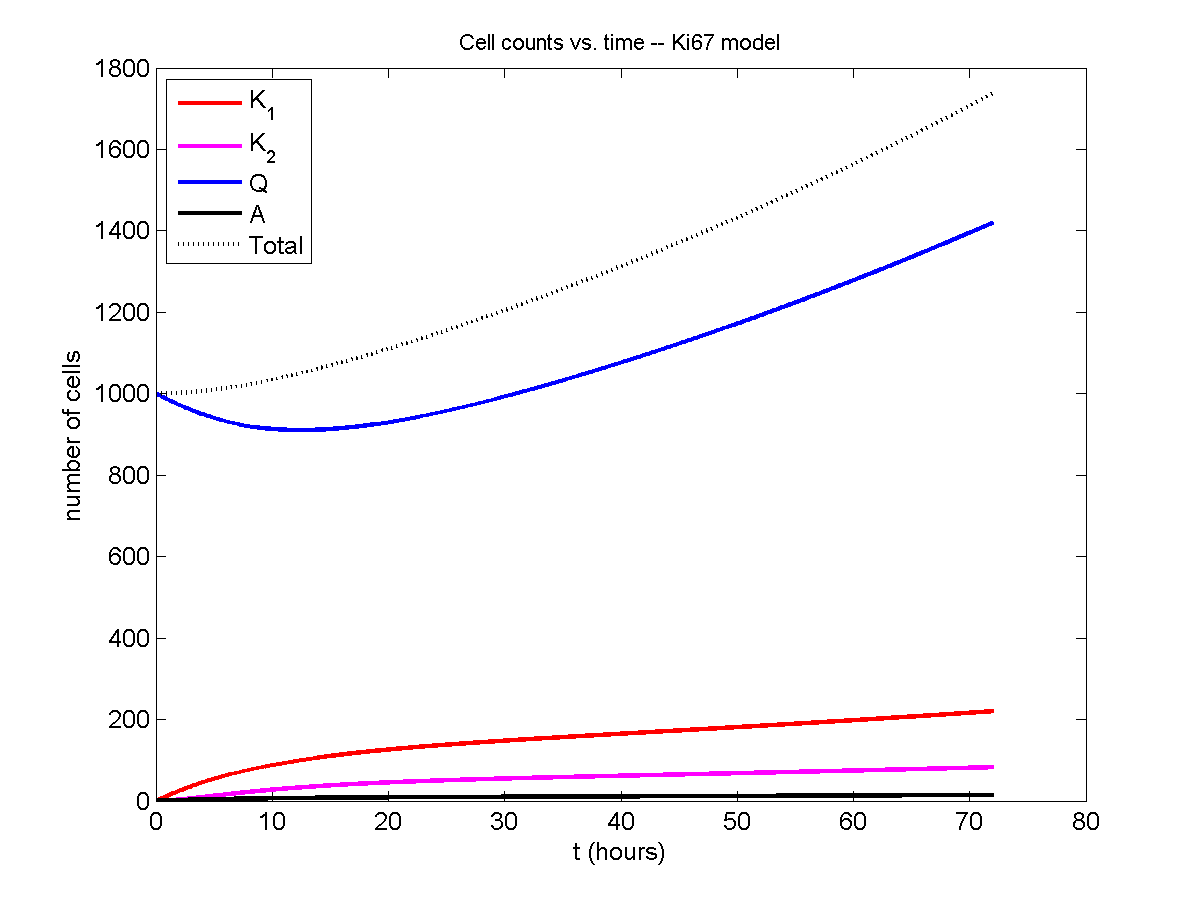
Next, we plot KI1, KI2, and AI versus time (solid curves), along with the theoretical long-time behavior (dashed curves). Notice how well it matches–it’s neat when theory works! :-)
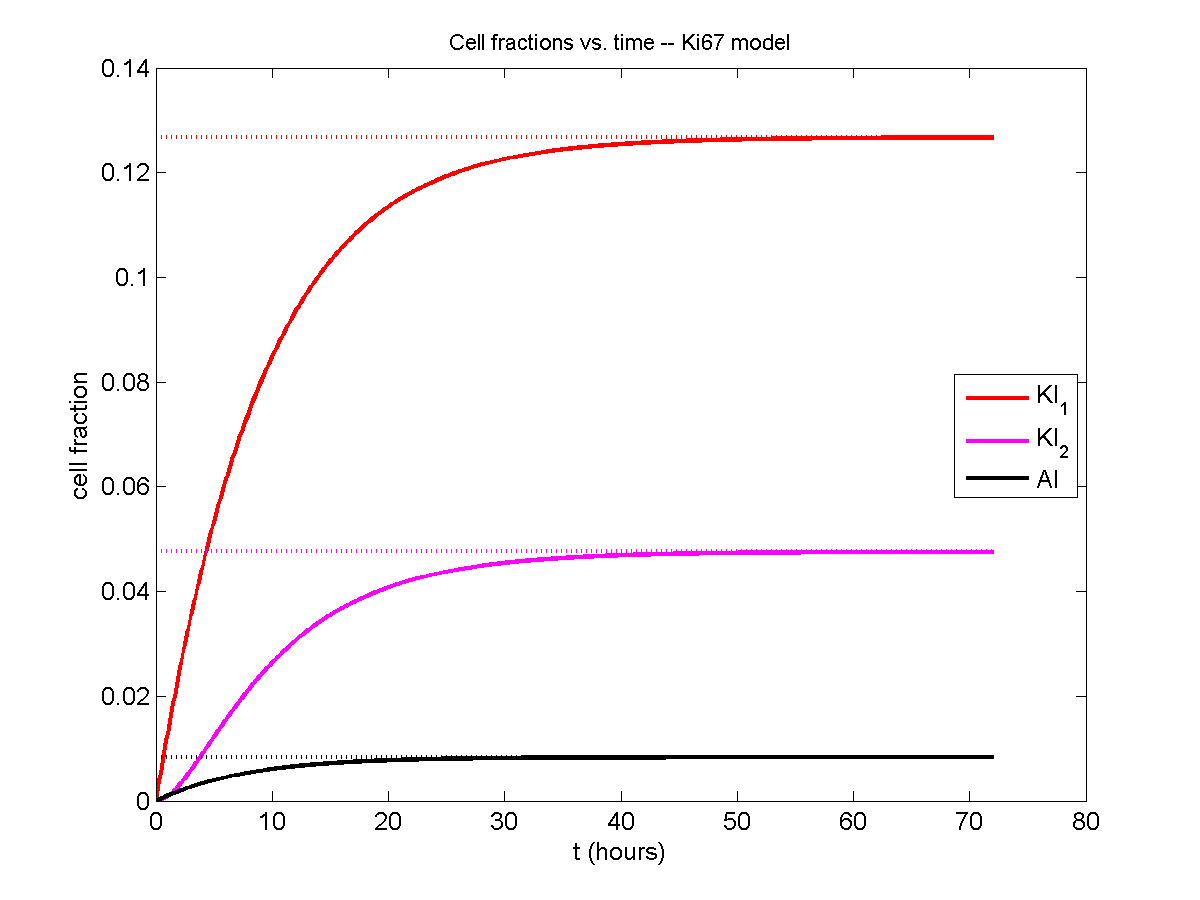
Some readers may recognize the long-time fractions: KI1 + KI2 = KI = 0.1743, and AI = 0.00833, very close to the DCIS patient values from our simulation study in Macklin et al. (2012) and improved calibration work in Hyun and Macklin (2013).
Comparing simulations and theory
I wrote a small Matlab program to implement the discrete model: start with 1000 cells in the \(Q\) phase, and in each time interval \([t,t+\Delta t]\), each cell “decides” whether to advance to the next phase, stay in the same phase, or apoptose. If we compare a single run against the theoretical curves, we see hints of a match:
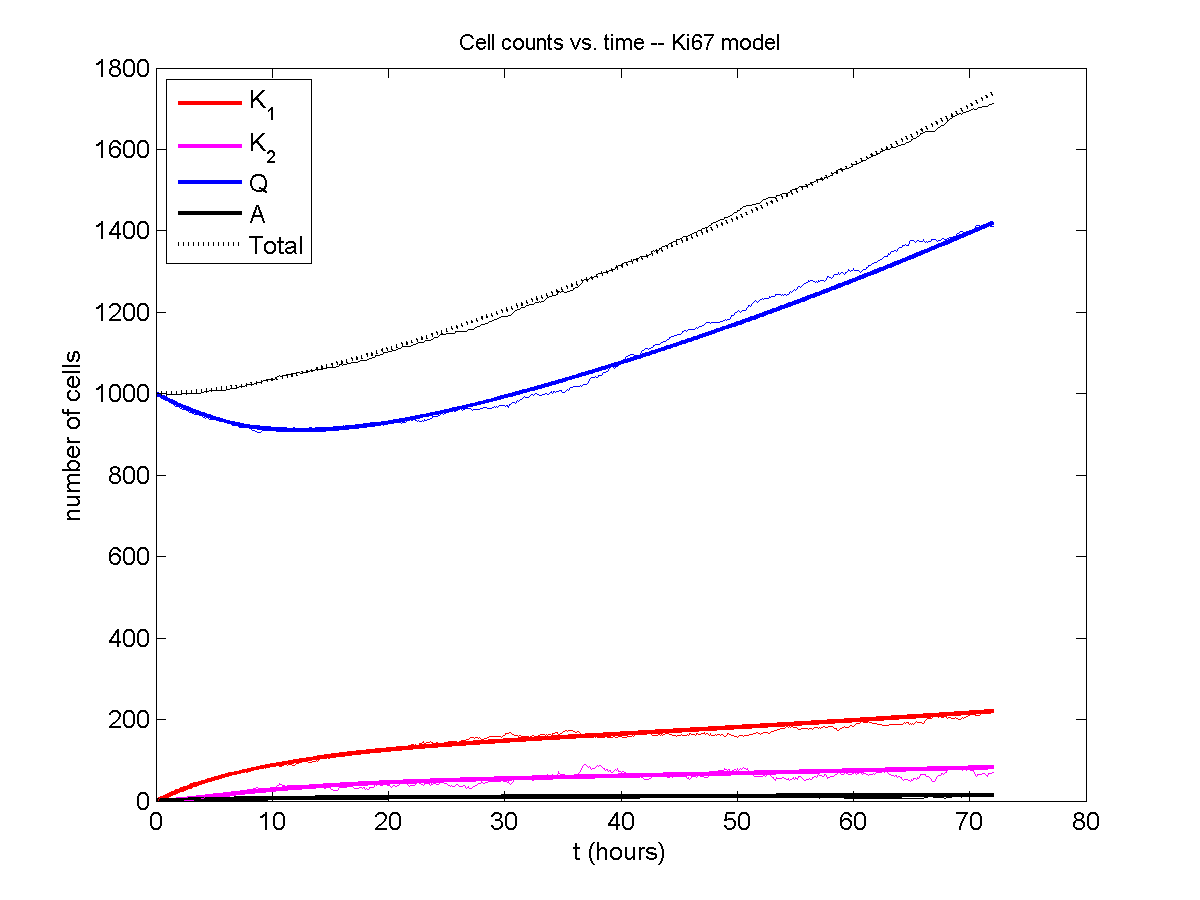
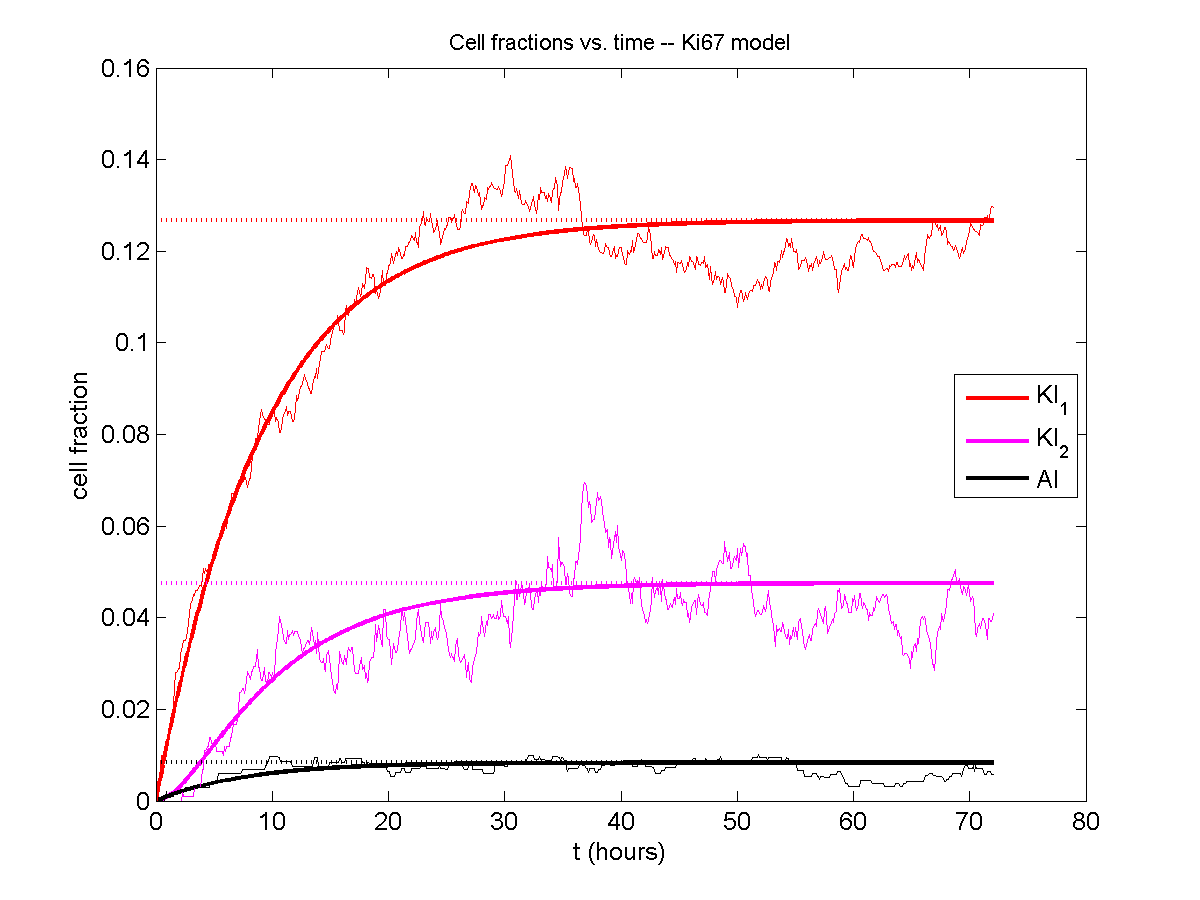
If we average 10 simulations and compare, the match is better:

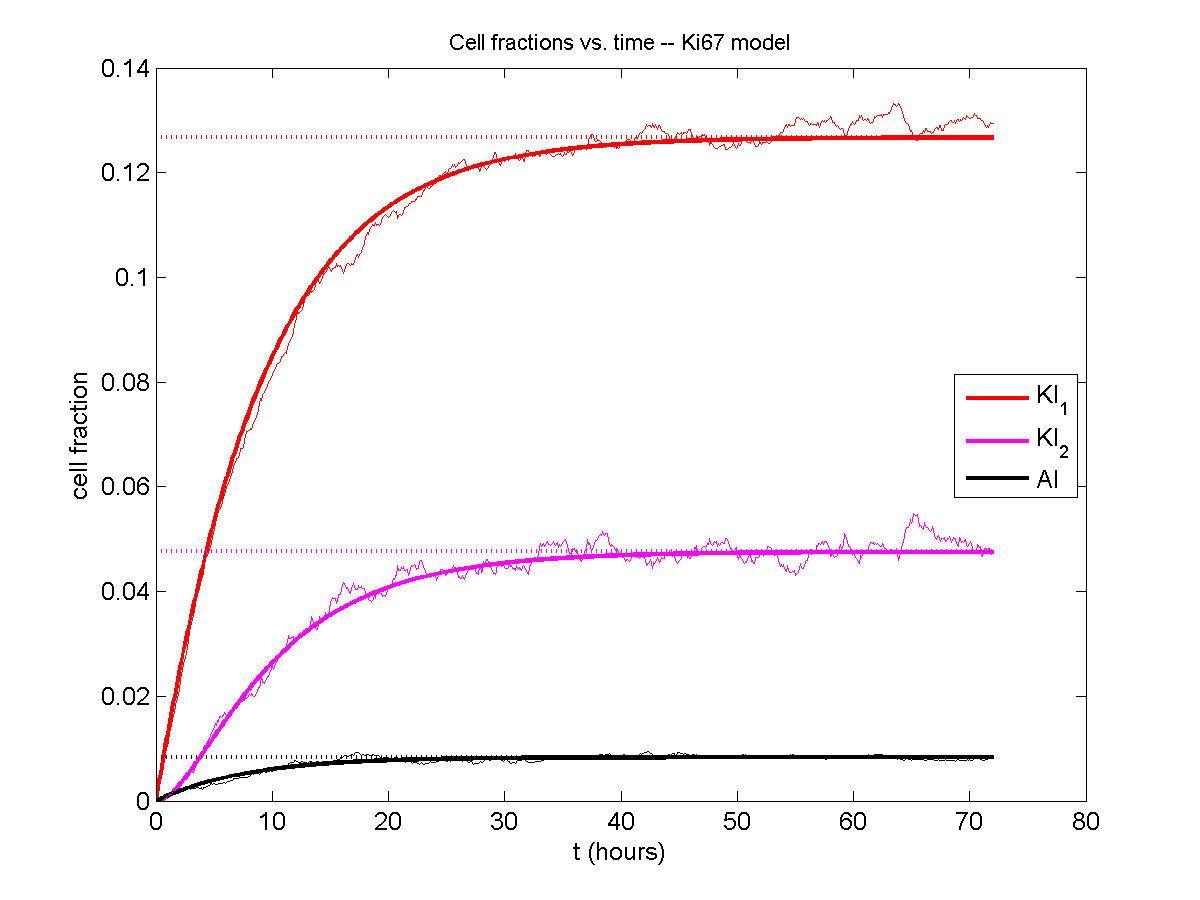
And lastly, if we average 100 simulations and compare, the curves are very difficult to tell apart:
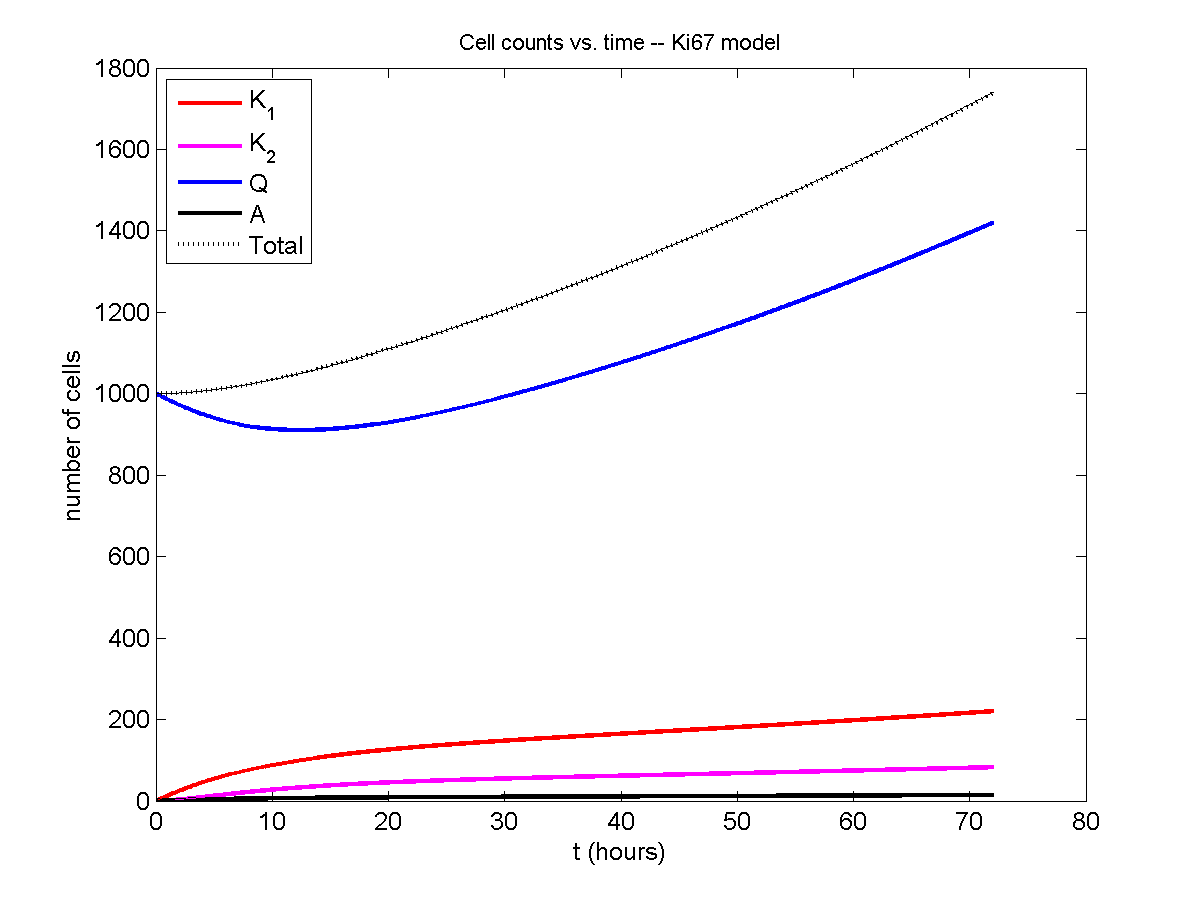

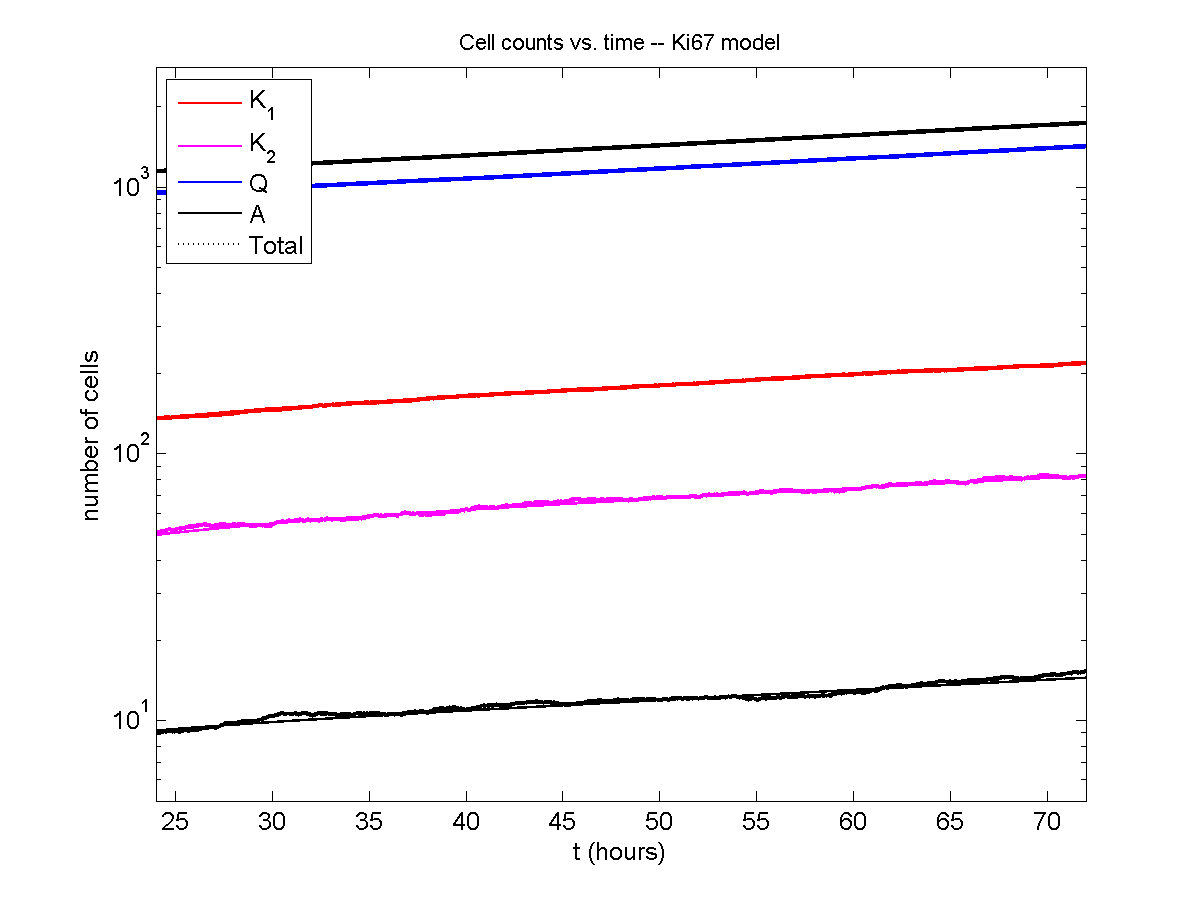
Even in logarithmic space, it’s tough to tell these apart:
Code
The following matlab files (available here) can be used to reproduce this post:
- Ki67_exact.m
- The function defined above to create the exact solution using the eigenvalue/eignvector approach.
- Ki67_stochastic.m
- Runs a single stochastic simulation, using the supplied parameters.
- script.m
- Runs the theoretical solution first, creates plots, and then runs the stochastic model 100 times for comparison.
To make it all work, simply run “script” at the command prompt. Please note that it will generate some png files in its directory.
Closing thoughts
In this post, we showed a nice way to check a discrete model against theoretical behavior–both in short-term dynamics and long-time behavior. The same work should apply to validating many discrete models. However, when you add spatial effects (e.g., a cellular automaton model that won’t proliferate without an empty neighbor site), I wouldn’t expect a match. (But simulating cells that initially have a “salt and pepper”, random distribution should match this for early times.)
Moreover, models with deterministic phase durations (e.g., K1, K2, and A have fixed durations) aren’t consistent with the ODE model above, unless the cells they are each initialized with a random amount of “progress” in their initial phases. (Otherwise, the cells in each phase will run synchronized, and there will be fixed delays before cells transition to other phases.) Delay differential equations better describe such models. However, for long simulation times, the slopes of the sub-populations and the cell fractions should start to better and better match the ODE models.
Now that we have verified that the discrete model is performing as expected, we can have greater confidence in its predictions, and start using those predictions to assess the underlying models. In ODE and PDE models, you often validate the code on simpler problems where you have an analytical solution, and then move on to making simulation predictions in cases where you can’t solve analytically. Similarly, we can now move on to variants of the discrete model where we can’t as easily match ODE theory (e.g., time-varying rate parameters, spatial effects), but with the confidence that the phase transitions are working as they should.
Some quick math to calculate numerical convergence rates
I find myself needing to re-derive this often enough that it’s worth jotting down for current and future students. :-)
Introduction
A very common task in our field is to assess the convergence rate of a numerical algorithm: if I shrink \(\Delta t\) (or \(\Delta x\)), how quickly does my error shrink? And in fact, does my error shrink? Assuming you have a method to compute the error for a simulation (say, a simple test case where you know the exact solution), you want a fit an expression like this:
\[ \mathrm{Error}(\Delta t) = C \Delta t^n ,\] where \( C\) is a constant, and \( n \) is the order of convergence. Usually, if \( n \) isn’t at least 1, it’s bad.
So, suppose you are testing an algorithm, and you have the error \( E_1 \) for \( \Delta t_1 \) and \( E_2 \) for \( \Delta t_2 \). Then one way to go about this calculation is to try to cancel out \( C\):
\begin{eqnarray} \frac{ E_1}{E_2} = \frac{C \Delta t_1^n }{C \Delta t_2^n } = \left( \frac{ \Delta t_1 }{\Delta t_2} \right)^n & \Longrightarrow & n = \frac{ \log\left( E_1 / E_2 \right) }{ \log\left( \Delta t_1 / \Delta t_2 \right) } \end{eqnarray}
Another way to look at this problem is to rewrite the error equation in log-log space:
\begin{eqnarray} E = C \Delta t^N & \Longrightarrow & \log{E} = \log{C} + n \log{ \Delta t} \end{eqnarray}
so \(n\) is the slope of the equation in log space. If you only have two points, then,
\[ n = \frac{ \log{E_1} – \log{E_2} }{ \log{\Delta t_1} – \log{\Delta t_1} } = \frac{ \log\left( E_1 / E_2 \right) }{ \log\left( \Delta t_1 / \Delta t_2 \right) }, \] and so we end up with the exact same convergence rate as before.
However, if you have calculated the error \( E_i \) for a whole bunch of values \( \Delta t_i \), then you can extend this idea to get a better sense of the overall convergence rate for all your values of \( \Delta t \), rather than just two values. Just find the linear least squares fit to the points \( \left\{ ( \log\Delta t_i, \log E_i ) \right\} \). If there are just two points, it’s the same as above. If there are many, it’s a better representation of overall convergence.
Trying it out
Let’s demonstrate this on a simple test problem:
\[ \frac{du}{dt} = -10 u, \hspace{.5in} u(0) = 1.\]
We’ll simulate using (1st-order) forward Euler and (2nd-order) Adams-Bashforth:
dt_vals = [.2 .1 .05 .01 .001 .0001];
min_t = 0;
max_t = 1;
lambda = 10;
initial = 1;
errors_forward_euler = [];
errors_adams_bashforth = [];
for j=1:length( dt_vals )
dt = dt_vals(j);
T = min_t:dt:max_t;
% allocate memory
solution_forward_euler = zeros(1,length(T));
solution_forward_euler(1) = initial;
solution_adams_bashforth = solution_forward_euler;
% exact solution
solution_exact = initial * exp( -lambda * T );
% forward euler
for i=2:length(T)
solution_forward_euler(i) = solution_forward_euler(i-1)...
- dt*lambda*solution_forward_euler(i-1);
end
% adams-bashforth -- use high-res Euler to jump-start
dt_fine = dt * 0.1;
t = min_t + dt_fine;
temp = initial ;
for i=1:10
temp = temp - dt_fine*lambda*temp;
end
solution_adams_bashforth(2) = temp;
for i=3:length(T)
solution_adams_bashforth(i) = solution_adams_bashforth(i-1)...
- 0.5*dt*lambda*( 3*solution_adams_bashforth(i-1)...
- solution_adams_bashforth(i-2 ) );
end
% Uncomments if you want to see plots.
% figure(1)
% clf;
% plot( T, solution_exact, 'r*' , T , solution_forward_euler,...
% 'b-o', T , solution_adams_bashforth , 'k-s' );
% pause ;
errors_forward_euler(j) = ...
max(abs( solution_exact - solution_forward_euler ) );
errors_adams_bashforth(j) = ...
max(abs( solution_exact - solution_adams_bashforth ) );
end
Here is a plot of the errors:
figure(2)
loglog( dt_vals, errors_forward_euler, 'b-s' ,...
dt_vals, errors_adams_bashforth, 'r-o' ,...
'linewidth', 2 );
legend( 'Forward Euler', 'Adams-Bashforth' , 4 );
xlabel( '\Delta t (log scale)' , 'fontsize', 14 );
ylabel( 'Absolute errors (log scale)', 'fontsize', 14 );
title( 'Errors vs. \Delta t', 'fontsize' , 16 );
set( gca, 'fontsize' , 14 );
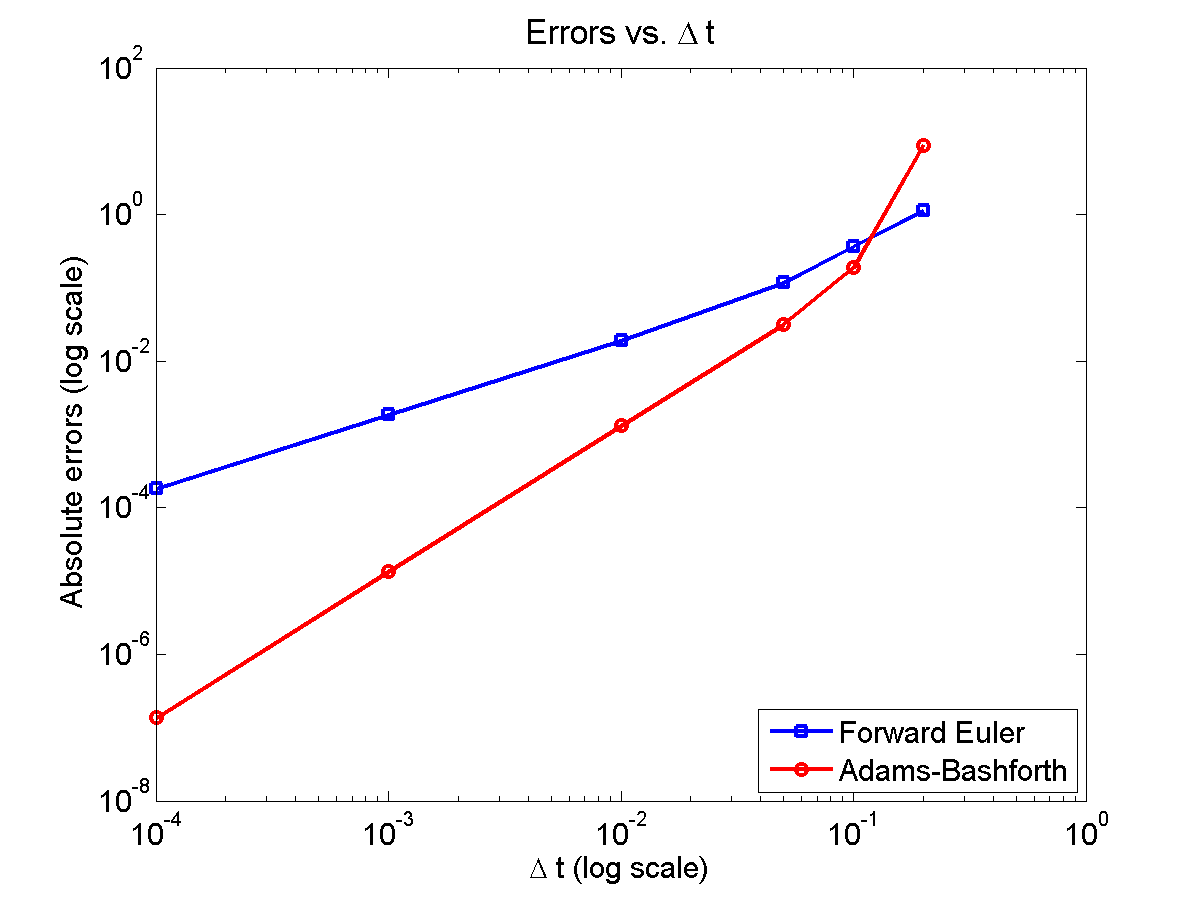
Note that calculating the convergence rate based on the first two errors, and first and last errors, is not terribly
representative, compared with using all the errors:
% Convergence rate based on the first two errors
polyfit( log(dt_vals(1:2)) , log(errors_forward_euler(1:2)) , 1 )
polyfit( log(dt_vals(1:2)) , log(errors_adams_bashforth(1:2)) , 1 )
% Convergence rate based on the first and last errors
m = length(dt_vals);
polyfit( log( [dt_vals(1),dt_vals(m)] ) ,...
log( [errors_forward_euler(1),errors_forward_euler(m)]) , 1 )
polyfit( log( [dt_vals(1),dt_vals(m)] ) ,...
log( [errors_adams_bashforth(1),errors_adams_bashforth(m)]) , 1 )
% Convergence rate based on all the errors
polyfit( log(dt_vals) , log(errors_forward_euler) , 1 )
polyfit( log(dt_vals) , log(errors_adams_bashforth) , 1 )
% Convergence rate based on all the errors but the outlier
polyfit( log(dt_vals(2:m)) , log(errors_forward_euler(2:m)) , 1 )
polyfit( log(dt_vals(2:m)) , log(errors_adams_bashforth(2:m)) , 1 )
Using the first two errors gives a convergence rate over 5 for Adams-Bashforth, and around 1.6 for forward Euler. Using first and last is better, but still over-estimates the convergence rates (1.15 and 2.37, FE and AB, respectively). Linear least squares is closer to reality: 1.12 for FE, 2.21 for AB. And lastly, linear least squares but excluding the outliers, we get 1.08 for forward Euler, and 2.03 for Adams-Bashforth. (As expected!)
Which convergence rates are “right”?
So, which values do you report as your convergence rates? Ideally, use all the errors to avoid bias and/or cherry-picking. It’s the most honest and straightforward way to present the work. However, you may have a good rationale to exclude the clear outliers in this case. But then again, if you have calculated the errors for enough values of \(\Delta t\), there’s no need to do this at all. There’s little value in (or basis for) reporting the convergence rate to three significant digits. I’d instead report these as approximately first-order convergence (forward Euler) and approximately second-order convergence (Adams-Bashforth); we get this result with either linear least squares fit, and using all your data points puts you on more solid ground.
Return to News • Return to MathCancer • Follow @MathCancer